1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
|
import logging
from selenium.webdriver.chrome.service import Service
import schedule
import random
import time
import os
from datetime import datetime
import pickle
from itertools import product
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
import undetected_chromedriver as uc
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
import sys
foreign1_dir = "E:/suno/MergeLyric"
foreign2_dir = "E:/suno/null"
lyrical_file = "E:/suno/musicstyle/Lyrical.txt"
emotion_file = "E:/suno/musicstyle/Emotion.txt"
orchestral_file = "E:/suno/musicstyle/Orchestral.txt"
chinese1_file = "E:/suno/null/null.txt"
chinese2_file = "E:/suno/null/null.txt"
state_file = "task_state.pkl"
log_filename = f"{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}.txt"
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', handlers=[
logging.FileHandler(log_filename, 'w', 'utf-8'),
logging.StreamHandler(sys.stdout)
])
options = Options()
options.add_argument('lang=zh_CN.UTF-8')
options.add_argument('--ignore-certificate-errors')
options.add_argument('--ignore-ssl-errors')
options.add_argument('user-agent="Mozilla/5.0 (iPod; U; CPU iPhone OS 2_1 like Mac OS X; ja-jp) AppleWebKit/525.18.1 (KHTML, like Gecko) Version/3.1.1 Mobile/5F137 Safari/525.20"')
options.add_argument(r'--user-data-dir=C:/Users/A/AppData/Local/Google/Chrome/User Data')
driver = uc.Chrome(options=options)
url = 'https://suno.com/create'
driver.get(url)
time.sleep(5)
combinations = []
task_count = 0
songtitle = 557
tasks_since_last_pause = 0
total_tasks = 0
def get_current_time():
return datetime.now().strftime("%Y-%m-%d %H:%M:%S")
def read_foreign_content(directory):
content_list = []
for filename in os.listdir(directory):
if filename.endswith(".txt"):
with open(os.path.join(directory, filename), 'r', encoding='utf-8') as file:
content = file.read().strip()
content_list.append(content)
logging.info(f"已读取 {len(content_list)} 个文件的内容来自 {directory}。")
return content_lis
def read_lines(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
lines = [line.strip() for line in file.readlines()]
logging.info(f"已读取 {len(lines)} 行内容来自 {file_path}。")
return lines
def read_whole_file(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read().strip()
logging.info(f"已读取文件内容来自 {file_path}。")
return content
def generate_combinations():
global combinations
foreign1_contents = read_foreign_content(foreign1_dir)
foreign2_contents = read_foreign_content(foreign2_dir)
lyrical_lines = read_lines(lyrical_file)
emotion_lines = read_lines(emotion_file)
orchestral_lines = read_lines(orchestral_file)
chinese1_content = read_whole_file(chinese1_file)
chinese2_content = read_whole_file(chinese2_file)
combinations = list(product(foreign1_contents, foreign2_contents, lyrical_lines, emotion_lines, orchestral_lines, [chinese1_content], [chinese2_content]))
logging.info(f"已生成 {len(combinations)} 个组合。")
def save_state():
with open(state_file, 'wb') as file:
pickle.dump((combinations, task_count, songtitle), file)
logging.info("任务状态已保存。")
def load_state():
global combinations, task_count, songtitle
if os.path.exists(state_file):
with open(state_file, 'rb') as file:
combinations, task_count, songtitle = pickle.load(file)
logging.info("恢复已保存的任务状态。")
else:
generate_combinations()
def perform_web_interaction(chinese1, foreign1, chinese2, foreign2, emotion, lyrical, orchestral):
try:
title = f"{songtitle}_{emotion}_{lyrical}_{orchestral}"
input_box_title = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//textarea[@placeholder="Enter a title"]'))
)
input_box_title.clear()
input_box_title.send_keys(title)
input_box1 = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//textarea[@placeholder="Enter your own lyrics or describe a song and click Write About..."]'))
)
input_box1.clear()
input_box1.send_keys(f"{foreign1}")
input_box2 = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//textarea[@placeholder="Enter style of music"]'))
)
input_box2.clear()
input_box2.send_keys(f"female vocal , {orchestral} , anime , {emotion} , {lyrical} ")
submit_button = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, "//button[.//span[text()='Create']]"))
)
submit_button.click()
time.sleep(2)
except Exception as e:
logging.error(f"Error during web interaction: {e}")
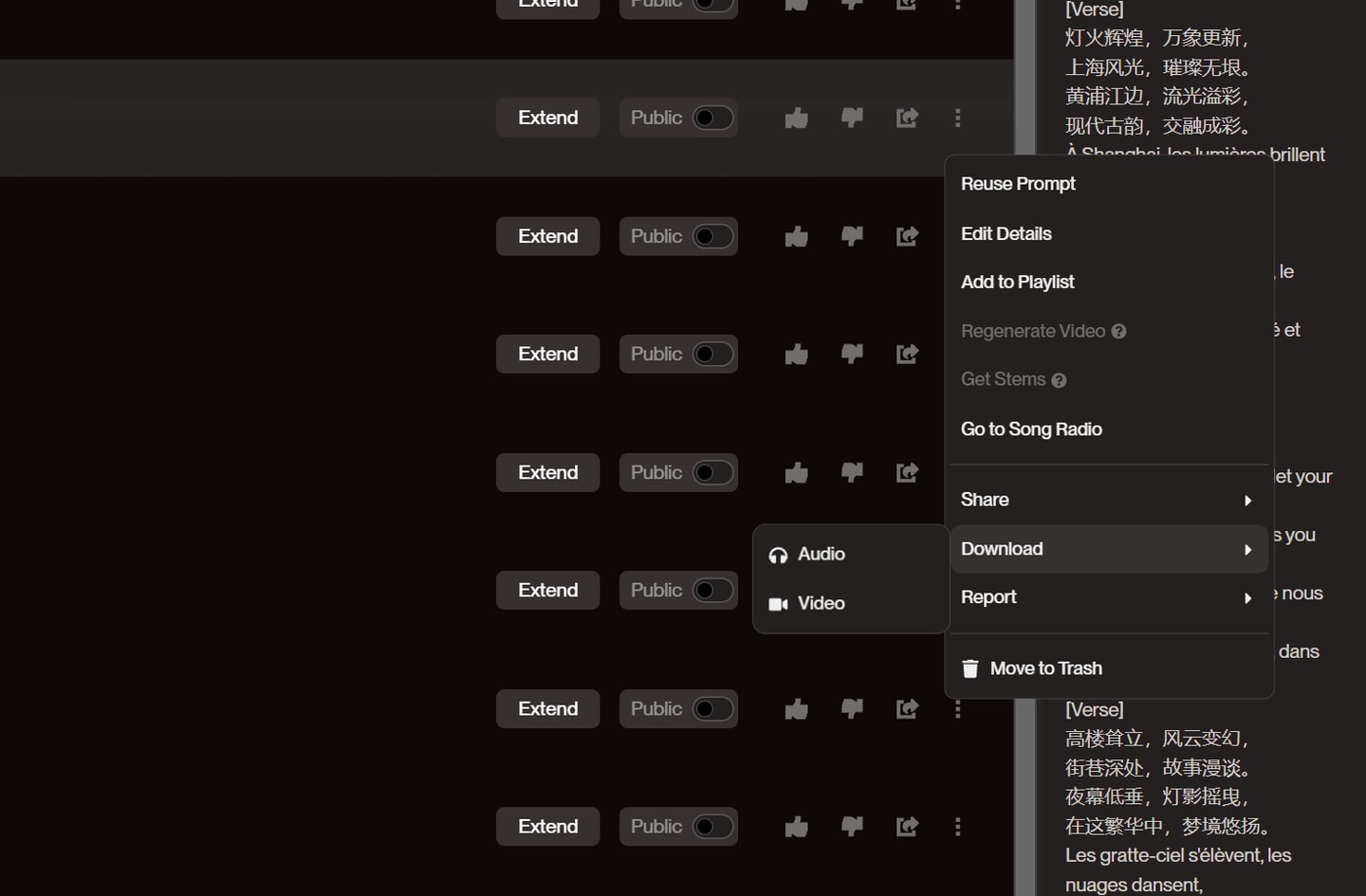
def download_music():
try:
spans = driver.find_elements(By.CSS_SELECTOR, "span[title]")
valid_spans = []
for span in spans:
title = span.get_attribute("title")
numeric_prefix = ''.join(filter(str.isdigit, title.split()[0]))
if numeric_prefix.isdigit():
valid_spans.append((span, int(numeric_prefix)))
sorted_spans = sorted(valid_spans, key=lambda x: x[1], reverse=True)
top_10_spans = sorted_spans[:10]
logging.info("即将下载的音乐:")
for span, _ in top_10_spans:
logging.info(span.get_attribute("title"))
for span, _ in top_10_spans:
parent_element = span.find_element(By.XPATH, "./../../..")
button = parent_element.find_element(By.XPATH, ".//button[contains(@style, 'width: 32px; height: 32px;') and @type='button']")
button.click()
time.sleep(2)
try:
download_option = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, "//*[text()='Download']"))
)
actions = ActionChains(driver)
actions.move_to_element(download_option).perform()
time.sleep(2)
audio_option = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, "//*[@data-testid='download-audio-menu-item']"))
)
actions = ActionChains(driver)
actions.move_to_element(download_option).perform()
time.sleep(2)
audio_option.send_keys(Keys.ENTER)
time.sleep(1)
audio_option.send_keys(Keys.ENTER)
logging.info(f"已成功下载音乐: {span.get_attribute('title')}")
except Exception as e:
logging.error(f"下载音乐 {span.get_attribute('title')}")
time.sleep(10)
except Exception as e:
logging.error(f"Error during music download: {e}")
def task():
global combinations, task_count, songtitle, tasks_since_last_pause, total_tasks
if combinations and total_tasks < 5:
foreign1, foreign2, lyrical, emotion, orchestral, chinese1, chinese2 = combinations.pop(0)
task_count += 1
total_tasks += 1
songtitle += 1
logging.info(f"{get_current_time()} - 执行任务 {task_count}: songtitle = '{songtitle}', chinese1 = '{chinese1}', foreign1 = '{foreign1}', chinese2 = '{chinese2}', foreign2 = '{foreign2}', Emotion = '{emotion}', Lyrical = '{lyrical}', Orchestral = '{orchestral}'")
perform_web_interaction(chinese1, foreign1, chinese2, foreign2, emotion, lyrical, orchestral)
if total_tasks >= 5:
logging.info(f"{get_current_time()} - 已执行 5 次提交,等待 300 秒后开始下载。\n\n")
time.sleep(300)
download_music()
total_tasks = 0
logging.info(f"{get_current_time()} - 所有音乐下载完毕,等待 180 秒后结束程序。\n\n")
time.sleep(90)
save_state()
time.sleep(90)
sys.exit()
else:
logging.info(f"{get_current_time()} - 未找到更多任务组合,任务结束。")
save_state()
sys.exit()
load_state()
job = schedule.every(2.6).minutes.do(task)
try:
while True:
schedule.run_pending()
time.sleep(1)
except KeyboardInterrupt:
save_state()
logging.info("程序已终止,状态已保存。")
|

评论