最近在啃ue的pbg程序化建筑以及matrix 项目中的材质是如何使用的。上周五感觉似乎到达了一个阶段,想先停一停脚步,喘口气。特别是matrix 的那个多层嵌套、超复杂的污渍分布系统配合两套uv、udim技术、4通道代表的4种污渍遮罩,如何去生成这些遮罩,如何展开部件的uv给到substance painter烘焙,如何在udmi上面铺开uv给出合理的block效果。
周五意外发现贴吧的帖子记录放开到了2001页,我看了下附近几页时间大概在2015年8月。想到之前用过大佬写的一个贴吧爬虫程序,当时是只有200页数据,内容太少了,便没什么兴致深究了,这次感觉有点意思。本地发现那个程序被我扔了,想到之前自己有过小的修改,所以到笔记本电脑拷贝了过来。没想到接下来被一系列bug整了一天,程序也没运行起来,这里面涉及到几个模块版本的问题,scrapy版本、cryptography、mysqlclient、parsel、pywin32,似乎是这些,我也不敢完全确定,可以看到aqua大佬的issue里面有个可怜的用户碰到的和我一样的也是在run.py里面出现add.option和add.argument版本兼容问题。不知道它有没有解决,这个项目已经被关闭禁止交流了。最后忘记安装rotate-proxies导致一直疯狂报错。
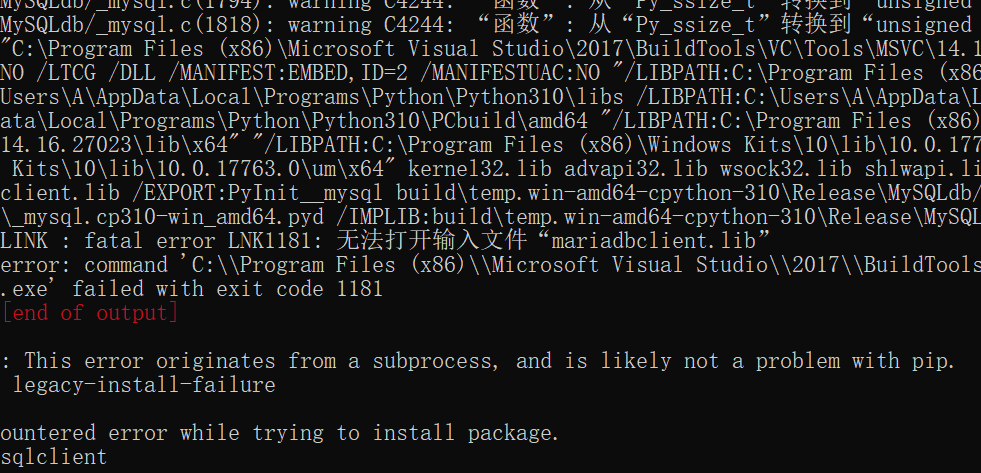
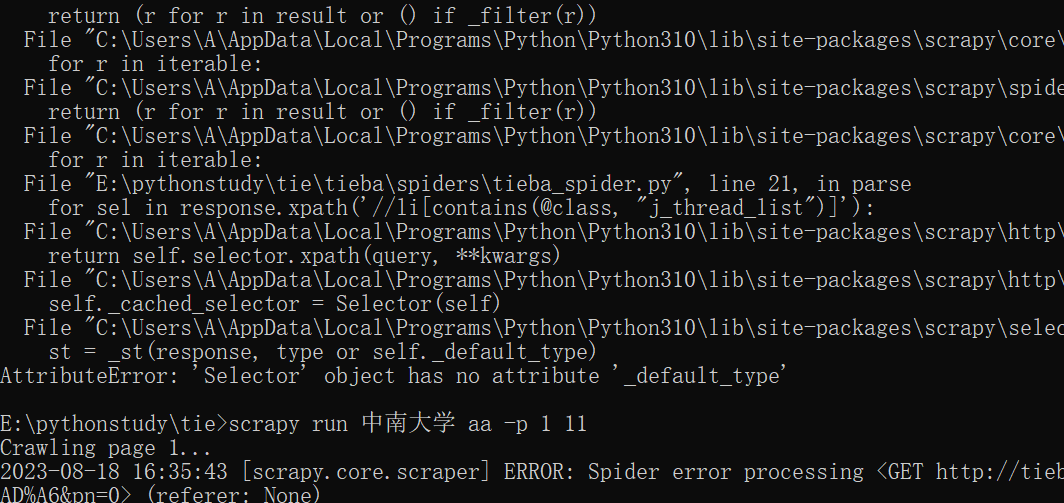
在程序终于可以跑起来后,周六日两天我都在人肉提交cmd命令行scrapy分段抓取帖子数据,因为超过一定页数代理就被封了,期间困在ip list、延迟时间设置、dataloss、enable retry,最后证明这些都没用,网上的免费代理构成的ip list根本抓取不到数据,我发现只有全局代理用clash买的代理可以有效抓取数据且速度很快,问题是如何把clash的代理构成iplist呢?暂时找不出来它的用户名密码,只用服务器+端口的格式不行。
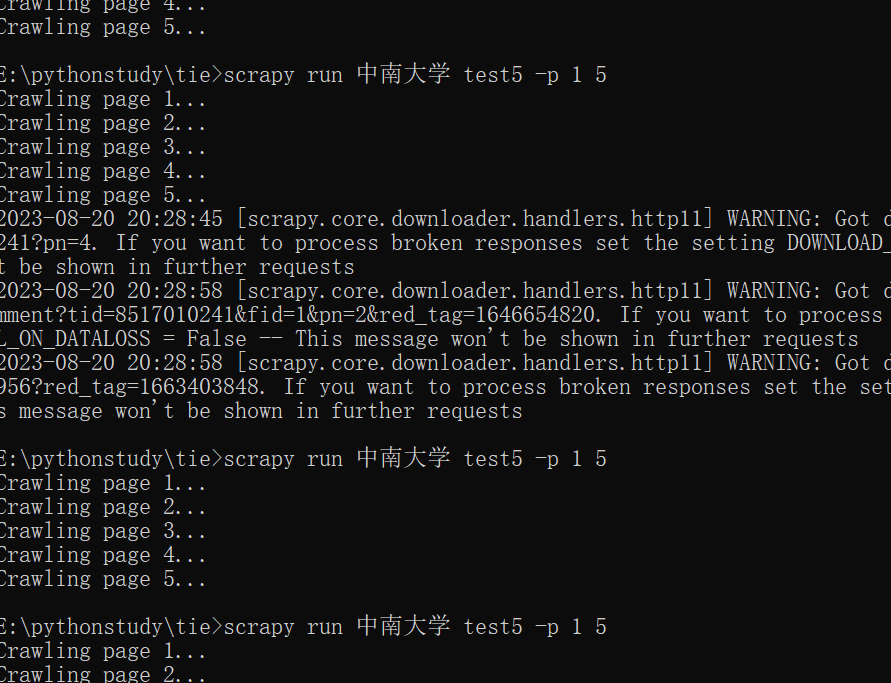
因此我8.18号总结:
没有必要用redis代理IP动态池和scrapy中间件来实现替换ip爬取贴吧数据,只要搞定clash定时自动切换ip即可。
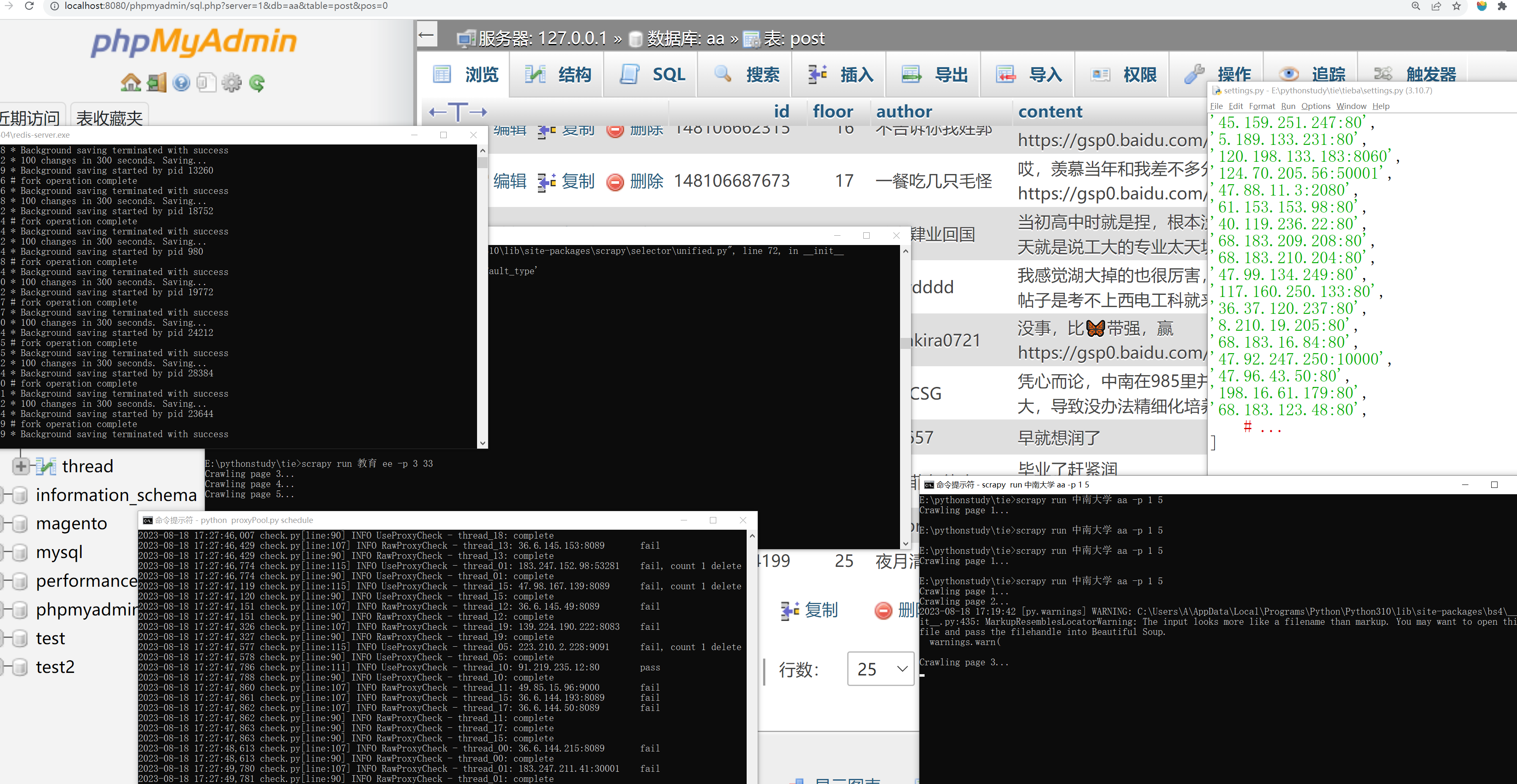
clash中的代理换一次大概可以抓取10页数据,然后会被百度封掉,不过大概几分钟后就会恢复过来,因此稍微手动续命可以傻瓜式的抓取数据。
phpmyadmin的数据库可以用mysqlworkbench连接,前提是在xammp面板中启动服务,workbench可以导出表格形式的网页这点比较舒服。phpmyadmin的mysql用户名密码在D:\xammp\phpMyAdmin\config.inc文件中,忘记了去那里找即可
昨天网上搜clash如何自动切换代理,结果基本都是关于url-test,还有很复杂的如何设置策略组、规则上的,脑子都转晕了,总的而言是为了代理不给力时自动切换,无法达成我要的定时切换,最后搜到通过external controller解锁http请求可以对代理进行自定义切换,我这里发现了clash.razord.top这个网站可以与本地的external controller适配,在它的页面上可以实现对代理的自定义选择!网上很多是用curl命令行去指定代理,既然是http请求,各种语言应该都不在话下,于是问题转换成了如何定时cmd键入scrapy动态化页码以及周期性提交http请求改变代理,代理应该打包成一个数组对象。
问题都被一一解决,其中卡在了只能在rule模式下改动global的代理,后来发现只要加上,其问题在于代理模式下的请求会出问题,python proxy 502用这个关键词成功找到了下面的解决方法。
做一个大的项目还是小的事儿,凡是卡住了,最关键的是要能够提出切中要害的问题,往往我们最大的问题就是不知道如何去提问,而这方面在中文搜索引擎中缺乏大量相关的信息,需要用英文提问来弥补,这类事儿chatgpt什么的暂时还是无能为力的。
1 | |
然后就是约束时间和页数问题了,经过多次人肉测试我发现每次抓取设定起始页与最后页,抓取后最后页基本全部抓取到了,而之前的几页往往都没了,所以我想设定页数少,保证每一页都有一次最后页的状态,然后目前看下来3分钟是肯定够抓取了,下一步我想是不是2分钟也能解决,毕竟要是3分钟1页的话,1天10小时得搞10几天,2分钟的话可以7天搞定。目前经过一轮所有代理的循环,36个ip有部分出现了问题,只抓了一页,这种情况我在人肉操作时发现是白干,于是我想第二轮验证看看是不是U开头的代理都不行,马上要去吃饭了还能看看电脑屏幕暗了是不是会断网休眠设置取消是否有效。
1 | import threading |
回来后发现2分钟间隔下载所有代理在一个周期后仍能正常运行,其中有2个代理似乎不正常但这两页数据似乎都到位了,计算机没有休眠,期间网络正常。那么自动抓取贴吧应该是没有问题了就按照这个设置,每天10小时,一小时30页,大约7天左右全部抓取结束。这个程序的好处是代理设置了循环顺序,可以根据当前使用的代理倒推恢复正常的代理,从而中断以后再恢复,做局部手动抓取调整。一般睡一觉最多后推2页,第二天倒推2页开始抓取即可。
不过连续开机的话24x30x3,3天就可以抓取完2000页了,我觉得可以试试看。
最终实验总结:
设计爬取页数在3页内可以基本保证全部抓取,当页数大于3页就开始出现部分丢失,那么当每隔一页步长递进,可以保障连续2个代理挂了依旧不丢失数据.
当16个代理互相间隔350秒时,也就是整个周期在1个半小时左右,一些挂掉的代理大概率能在下一轮周期复活,目前还没有测试把这个间隔再压缩能不能保障效果.总之目前这个设置可以完全自动跑了,就是速度慢了些。
评论