目前实测了3轮2.5小时也就是9000秒期间没有发生退出,都完整运行下来了,运行周期是3.1minutes/次,后两次测试发生了大量的队列占满不知道是不是频次太高?还需要进一步测试来确定,如果这个测试没问题,从早上8点开始到10.30一次,10.30到下午1点,1点到3.30,4点-7点。一天这么4轮感觉差不多,每40分钟断一次去折腾感觉还是会分神。
2024-8-20更新:
今天的3轮测试1次顺利。1次发生了不明原因的点击图片,导致后续出错,我不清楚这种情况是不是后续会自我调整回来从之前的记录看来好像是可以的。还有一次软件退出了。看来并不是完全稳定的,不过也不要太在意,总之继续观察运行状态。
blend使用方面经过这两天的测试,目前我想到的用法如下:
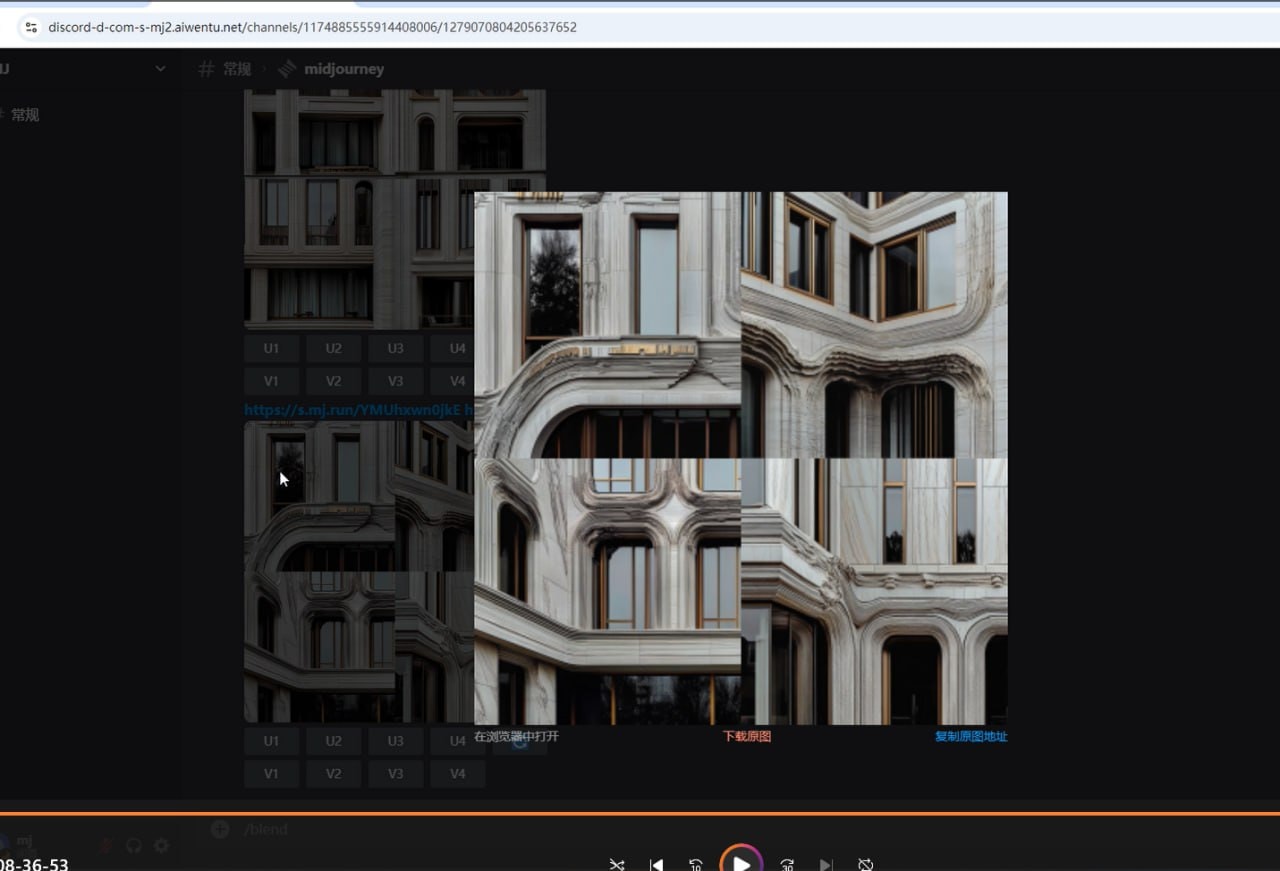
1.为整体建筑装饰添加某种色调或者图案风格,比如图2是由图1中从左到右的f1 f2 f3 blend而成,这种blend3通过两个建筑的整体结构和排布来定出建筑风格基调确保出图结果为建筑整体,可以看出来较为优秀的结果是由f1中的柱式cornice解析插图和中式古建筑彩画解析图引导而成的,图3用极为不规则的壁画或者像图1这个集成电路抽象艺术来引导,彩绘、色调的重排就会十分“剑走偏锋”从而使得绝大多数情况不尽如人意。那么由此可以推断,想要“小幅度”(我所认为的小幅度,实际上这种色调、彩绘涂装对于世界范围内的建筑装饰可以说已经是构成另一个体系了)的对建筑装饰的色调、彩绘做创新、个性化,那么f1的原料图引导应该是对f2、f3中目标建筑整体构建拆分后给出个性化涂装色彩,这种pattern book式的部件解析图网上有不少关键词可以去生成所以问题不大。
不过这是针对一个20240804这一批次blend测试的结论,我还没有用这个结论优化f1来验证,理想中状态可以把龙凤热带壁纸和芯片电路抽象图先设法弄到建筑部件解析图上然后再来blend3可以使这两种十分大胆、随意的彩绘布置到任意的建筑整体立面上。

阅读更多