最近发现家里附近2公里左右江宁路有个茑屋书店氛围不错去看了几次书,正当我对书店里的书做了一番准备想后期陆陆续续看时,我偶然间尝试用kimi概括整理电子书,发现它的概括整理还不错,花了一天时间手动复制章节给它概括。
chatgpt似乎不支持长文概括,或者说免费版的不支持,暂时还没找到可以免费用chatgpt4的办法。通义千问和kimi我测试后发现它虽然可以支持10几万字的长文本,但是长文本下要求概括章节则会发生假装概括的样子,比如让它概括第1章它会夹带其他章节的内容,为了使它的概括更为精确需要切分章节内容。手动搞,再一个个复制的话,一本40万字的书大约需要大半天完成。于是我想到自动切分章节,再用浏览器自动交互程序批量上传章节让kimi分析。
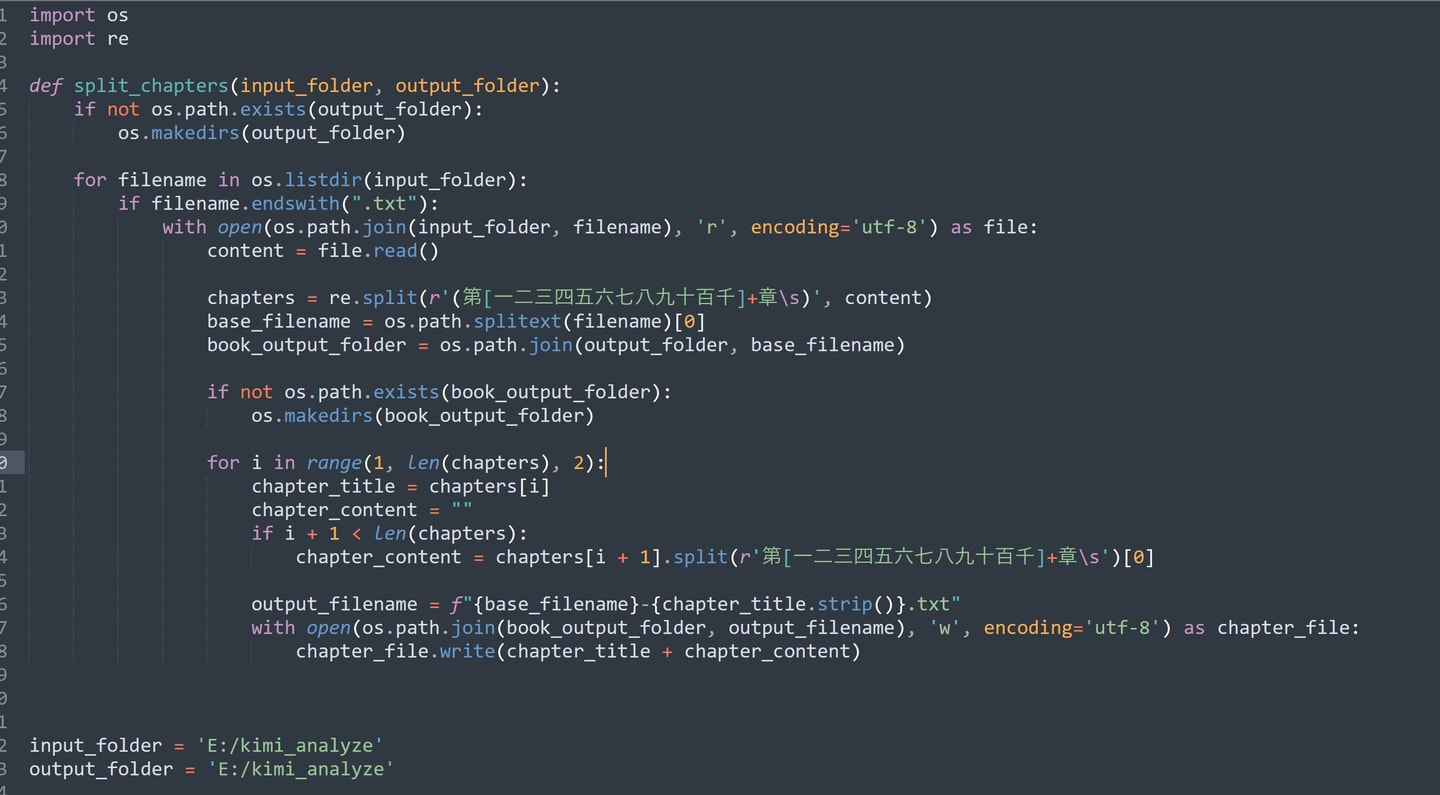
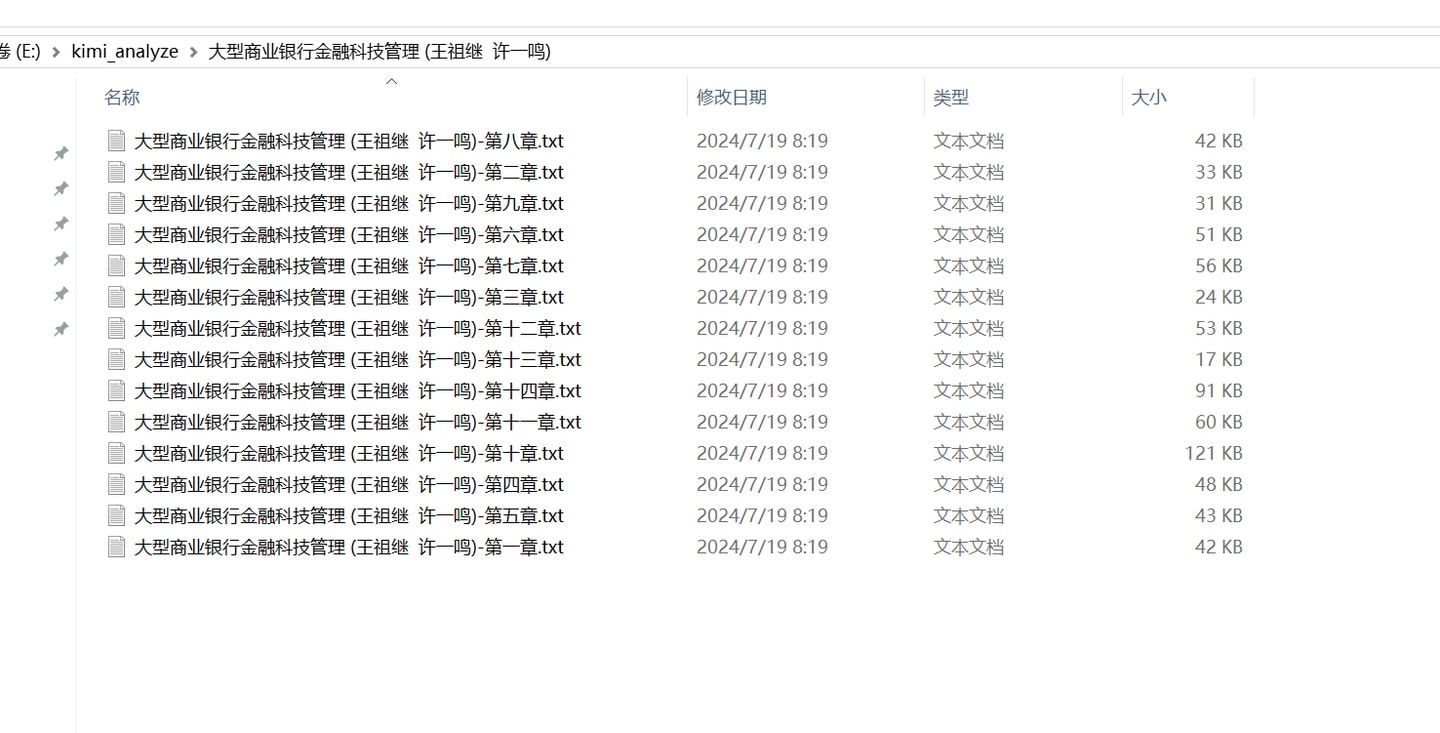
章节切分的逻辑是搜索第x章+“ ”(空格)到第x+1章+“ ”(空格),因为书中可能包含提及“第x章”的字符串因此首先要手动处理下每一章标题使其符合格式。通过这个程序能批量完成多本书的章节切分。
批量对指定文件夹下的txt书籍切分章节输出到对应名字的文件夹 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import osimport redef split_chapters (input_folder, output_folder ): if not os.path.exists(output_folder): os.makedirs(output_folder) for filename in os.listdir(input_folder): if filename.endswith(".txt" ): with open (os.path.join(input_folder, filename), 'r' , encoding='utf-8' ) as file: content = file.read() chapters = re.split(r'(第[一二三四五六七八九十百千]+章\s)' , content) base_filename = os.path.splitext(filename)[0 ] book_output_folder = os.path.join(output_folder, base_filename) if not os.path.exists(book_output_folder): os.makedirs(book_output_folder) for i in range (1 , len (chapters), 2 ): chapter_title = chapters[i] chapter_content = "" if i + 1 < len (chapters): chapter_content = chapters[i + 1 ].split(r'第[一二三四五六七八九十百千]+章\s' )[0 ] output_filename = f"{base_filename} -{chapter_title.strip()} .txt" with open (os.path.join(book_output_folder, output_filename), 'w' , encoding='utf-8' ) as chapter_file: chapter_file.write(chapter_title + chapter_content) input_folder = 'E:/kimi_analyze' output_folder = 'E:/kimi_analyze' split_chapters(input_folder, output_folder)
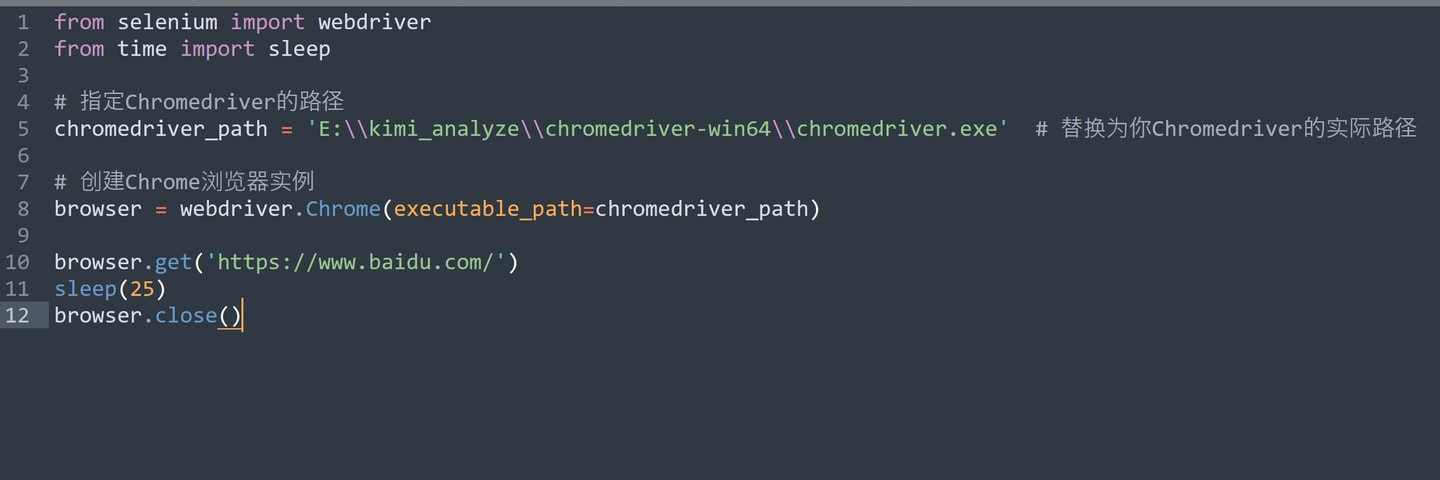
再然后是上传到kimi,这涉及到之前让我撤退的selenium,这次再上又碰壁了,可能有两个问题一个是chromedriver的路径要指定,不然的话可能与anaconda中的一些设定有冲突,另外selenium版本过高可能不适配chromedriver降低版本即可。先把这个打开百度测试通过。
再接下来要批量提交,这里涉及两个点,1是xpath把上传、提交按钮的html全部复制给chatgpt它很快解析出了xpath。程序虽然启动并打开了网页,但是kimi提示会话不显示,这应该是防爬虫的某种机制,网上搜了一会儿设置option,最后发现关键在于加上这句,options.add_argument(r’–user-data-dir=C:/Users/A/AppData/Local/Google/Chrome/User Data’),把我的个人上网环境加载进去模拟即可,这里的路径可以通过chrome://version/,在个人资料路径中获取去掉最后那个default即可。然后把chrome的启动改为空白页,(不然启动浏览器会优先按照上一次关闭的页面加载从而使程序逻辑出错)测试成功!实现了对批量段落的自动化批量提交分析概括。
批量提交指定文件夹下的文本给kimi做内容概括 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 import osimport timefrom selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.chrome.options import Optionschromedriver_path = 'E:\\kimi_analyze\\chromedriver-win64\\chromedriver.exe' options = Options() options.add_argument('lang=zh_CN.UTF-8' ) options.add_argument('user-agent="Mozilla/5.0 (iPod; U; CPU iPhone OS 2_1 like Mac OS X; ja-jp) AppleWebKit/525.18.1 (KHTML, like Gecko) Version/3.1.1 Mobile/5F137 Safari/525.20"' ) options.add_argument(r'--user-data-dir=C:/Users/A/AppData/Local/Google/Chrome/User Data' ) driver = webdriver.Chrome(executable_path=chromedriver_path, options=options) url = 'https://kimi.moonshot.cn/chat/cqcjh8ebi7s6s9mt6010' driver.get(url) time.sleep(5 ) folder_path = 'E:/kimi_analyze/娜塔莎之舞' files = os.listdir(folder_path) for file in files: file_path = os.path.join(folder_path, file) try : upload_button = WebDriverWait(driver, 5 ).until( EC.presence_of_element_located((By.XPATH, '//label[@data-testid="msh-chatinput-upload-button"]' )) ) upload_button.click() time.sleep(5 ) upload_input = driver.find_element(By.XPATH, '//input[@type="file"]' ) upload_input.send_keys(file_path) time.sleep(5 ) submit_button = driver.find_element(By.XPATH, '//button[@data-testid="msh-chatinput-send-button"]' ) submit_button.click() time.sleep(90 ) except Exception as e: print (f"Error occurred: {e} " ) driver.quit()

评论