stable diffusion我看了下文件夹的日期信息,我是在去年10月份下载的,midjourney等一众ai作图软件也是那个时间开始接触的。那个时候我只知道midjourney可以根据关键词生成图,可以根据参考图生成图,可以对选定的图生成类似创意图,stable diffusion可以根据关键词生成图。 stable diffusion有繁杂的设置,我都没去碰。
一年后的今天我现在遇到了一个问题——如何对一个小区的平面布局做设计?抛开复杂特殊的装饰,就平面摆放而言就算是极为复杂的分形几何艺术或各种有机雕塑,平面布局也就那样。无非绿化、小路、水景、建筑这几个元素怎么摆放和谐,但是要自己去设计思考着实头疼,且我自身缺乏这方面的专业性。若长期要对地块做布局设计,肯定力求一个能稳定控制风格且免费的软件,于是我又回头看了看stable diffusion。在b站上发现了有用ai做景观平面的教学,civitai.com上有许多ai模型。进而看了下stable diffusion关于建筑、室内、景观相关的系列教学。
首先原本的stable diffusion经过这一年经历了多次更新,原来的启动器可能跟不上时代了,跟上时代下载了b站秋叶aaaki的sd启动器,这个好像支持插件自动更新。根据言潇的教学似乎安装这个会加快图片生成速度。
最新版的stable diffusion,左上这个被称为底模型(言潇的教学)或者大模型(AI建筑研究室-贝熊)英文是checkpoint类型模型,在b站上有个大模型清单可以获取大模型,也可以在civitai上获取,这类模型从文件大小来看都是几个GB,文件后缀为.ckpt、.safetensors。每次切换大模型都需要30秒左右的样子,每次生成图片会自动保存到本地设定好的文件夹内。根据建筑学长的教学,大模型尽量选择safetensors格式,这种是新版的,ckpt为老版格式有安全隐患。pruned指精简版的模型。不同的大模型生成的效果非常不同。

什么是大模型呢?根据贝熊通过autoDL云端训练大模型的教学来看,就是通过一些肉眼看起来风格、主题接近的图片给它加上标签,然后给一个程序去循环迭代识别其特征,从而生成一个可以生产这种风格、主题图片的“精装房”。各种模型详解!大模型、微调Lora模型都是什么? | Stable Diffusion绘图教学_哔哩哔哩_bilibili
在b站建筑学长的这个教学中用毛坯房、精装房、二次装修来比喻官方的大模型、各种用户训练的大模型、嵌入式embeding,超网络,lora。其中embeding为打包的提示词,一些用户将十分长的提示词打包以后可以生成限定风格的图。建筑学长说embeding、超网络现在基本都没人用了。
lora和大模型有什么区别呢?从训练上来看它们似乎都是通过一些图片打标签放到一个程序里迭代。在用户AI-魔法师的教学中,他把lora比作一个客户对一个汉堡有要求想加番茄酱、生菜、辣椒,lora相当于额外增加了“层”,这里提到了“扩散模型”一层层的概念,lora在扩散模型中的层与层之间插入新的层,来影响输出结果。lora的权重建议是0.5左右或以下,看看作者使用的配套大模型,提示词、反向提示词,AI魔法师认为sd中反向提示词很关键。lora可以复合使用。
Stable Diffusion LORA模型知识点:什么是LORA?
训练所使用图片贝熊推荐是40-150张,言潇的演示中23张即可,贝熊认为最好是手动打标签定义图片中的元素,不过看起来这很麻烦我觉得还是直接用自动打tag的插件完成。

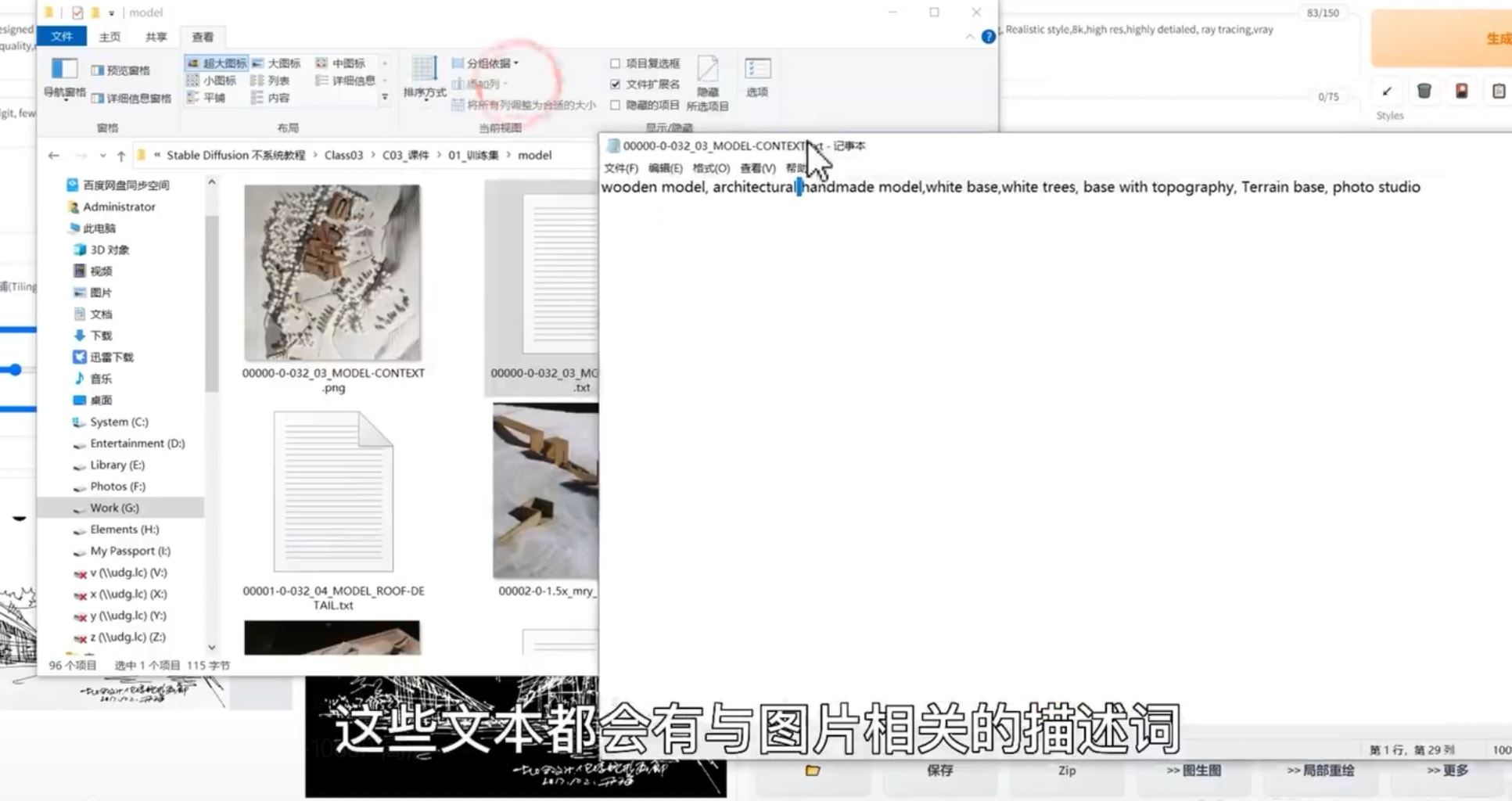
在训练栏目中进入图像预处理选择原始图片路径和输出路径,点blip生成标签,deepbooru是针对二次元的。关于模型训练后面再说。
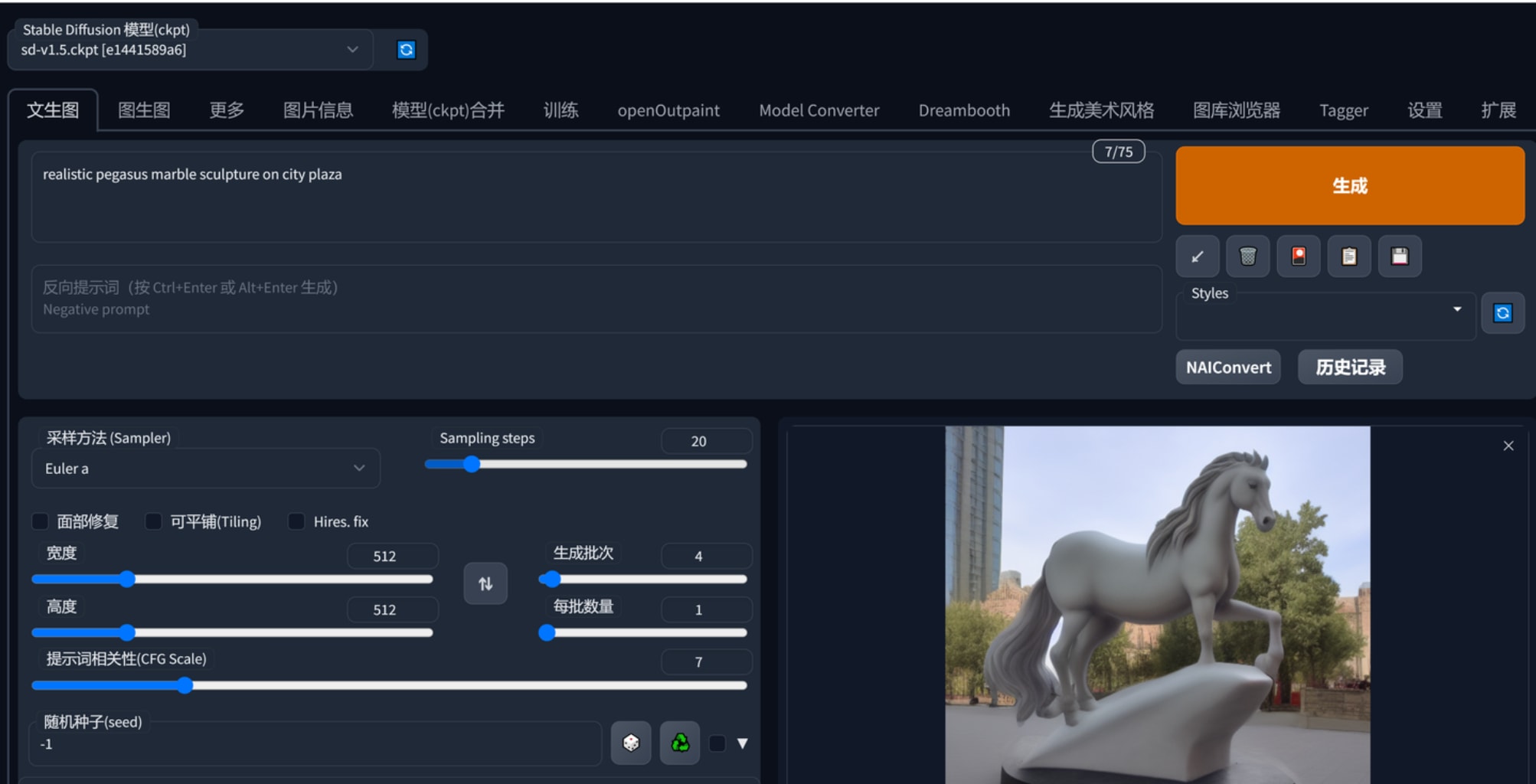
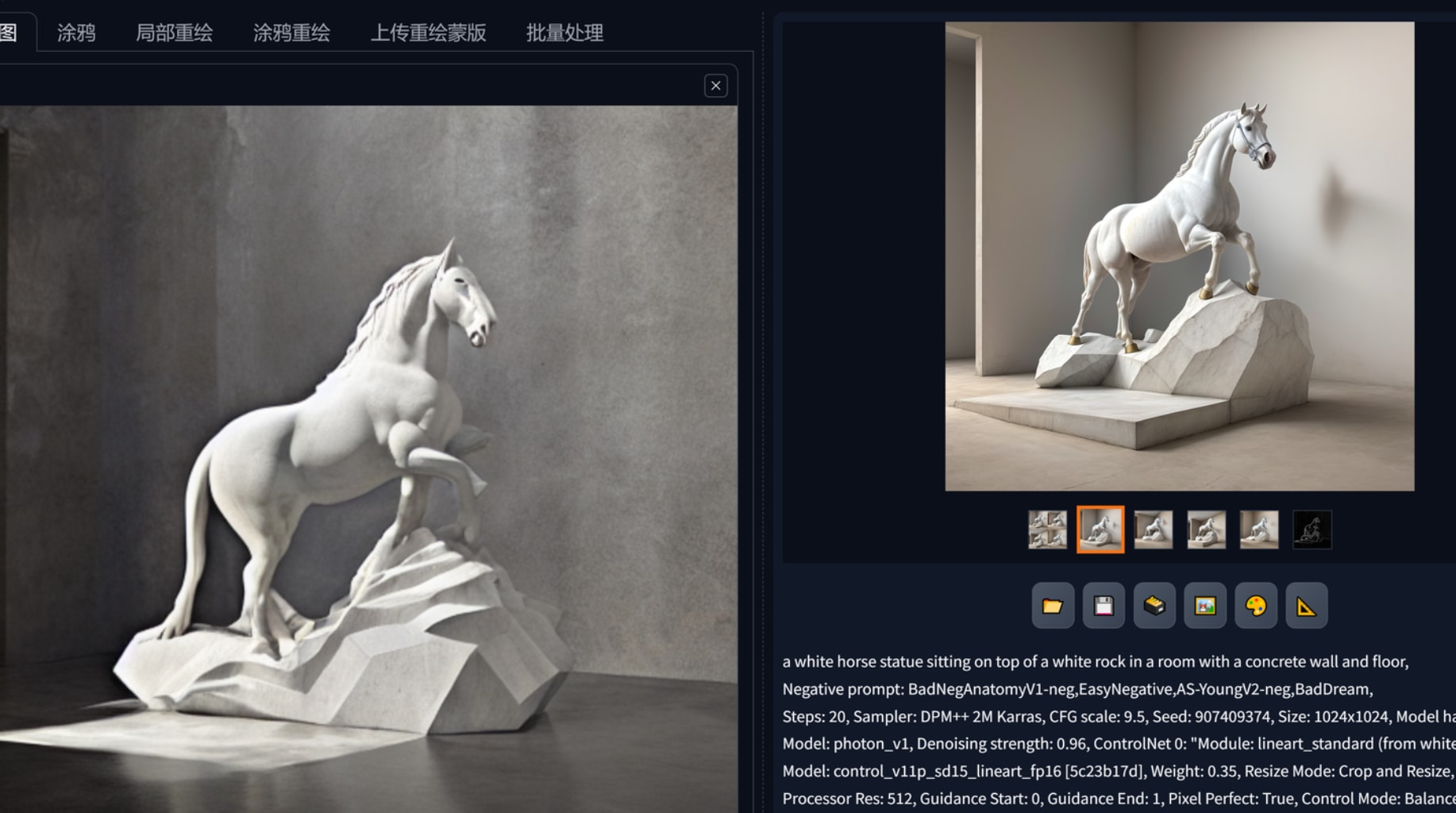
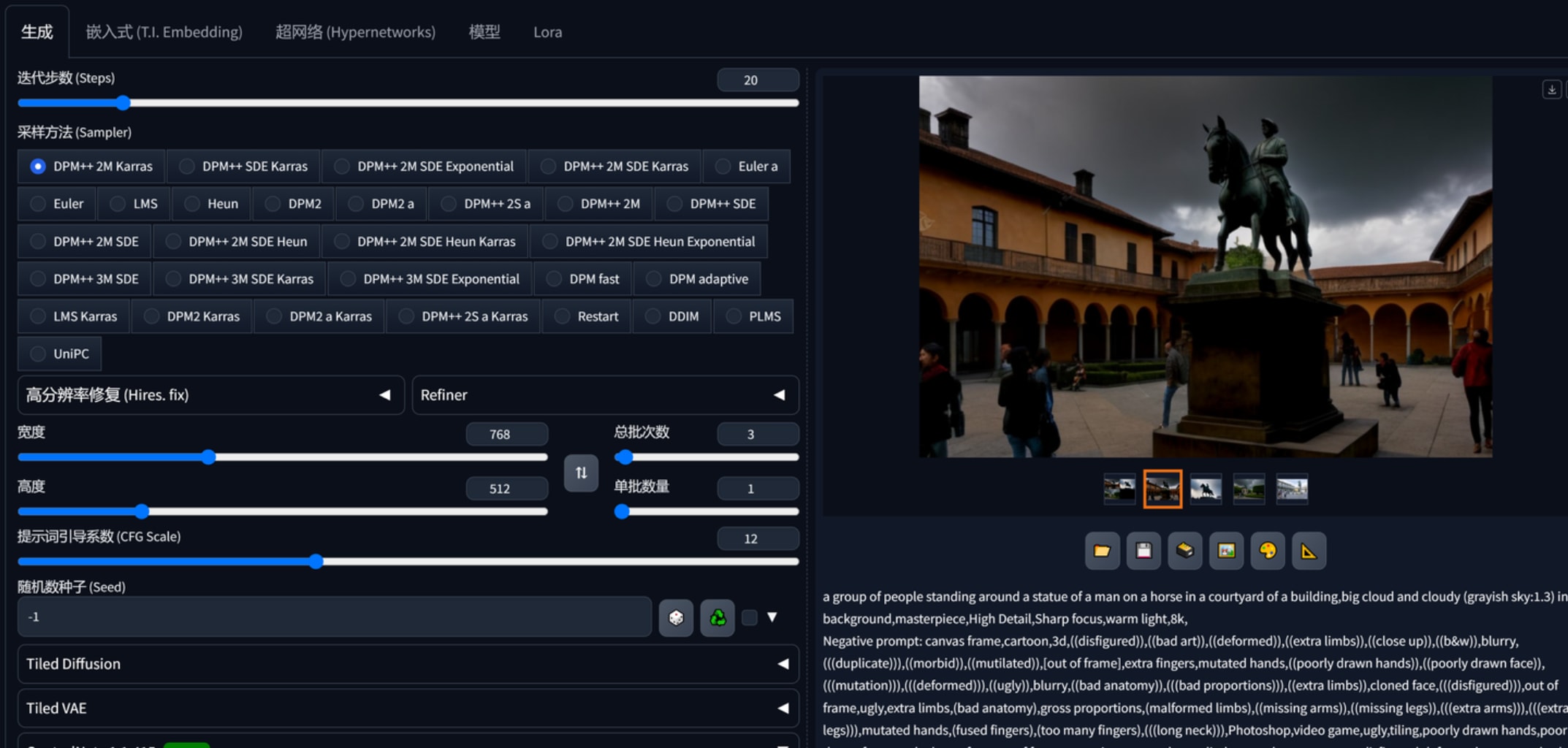
接着要谈谈如何精准控制图片的输出。提示词realistic pegasus marble sculpture生产了许多大理石天马雕塑的图,

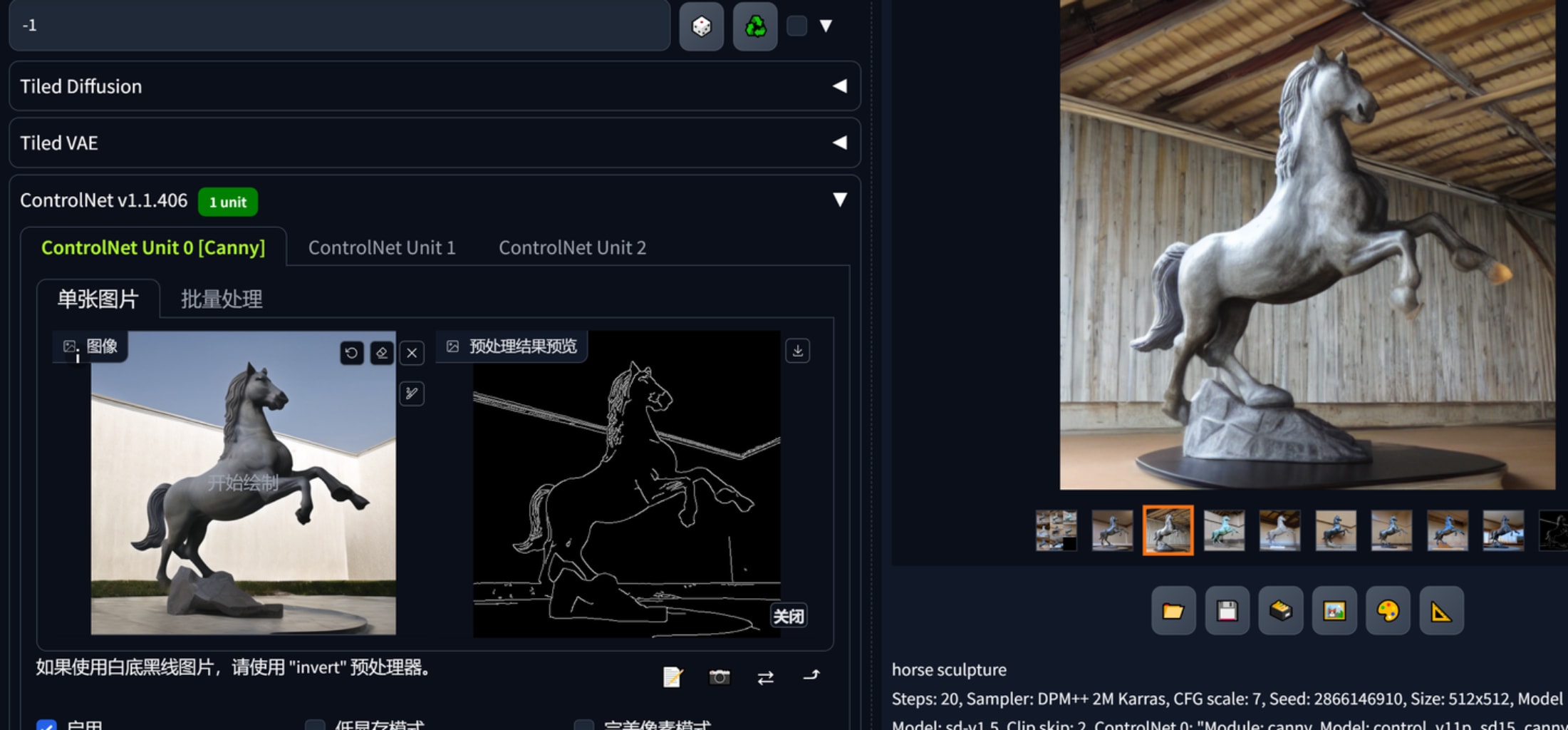
比如说我对其中一张觉得不错但想做部分修改,1是发送重绘,这种方法言潇不建议,他认为应该用controlnet中的lineart、depth、seg去精确控制图片。
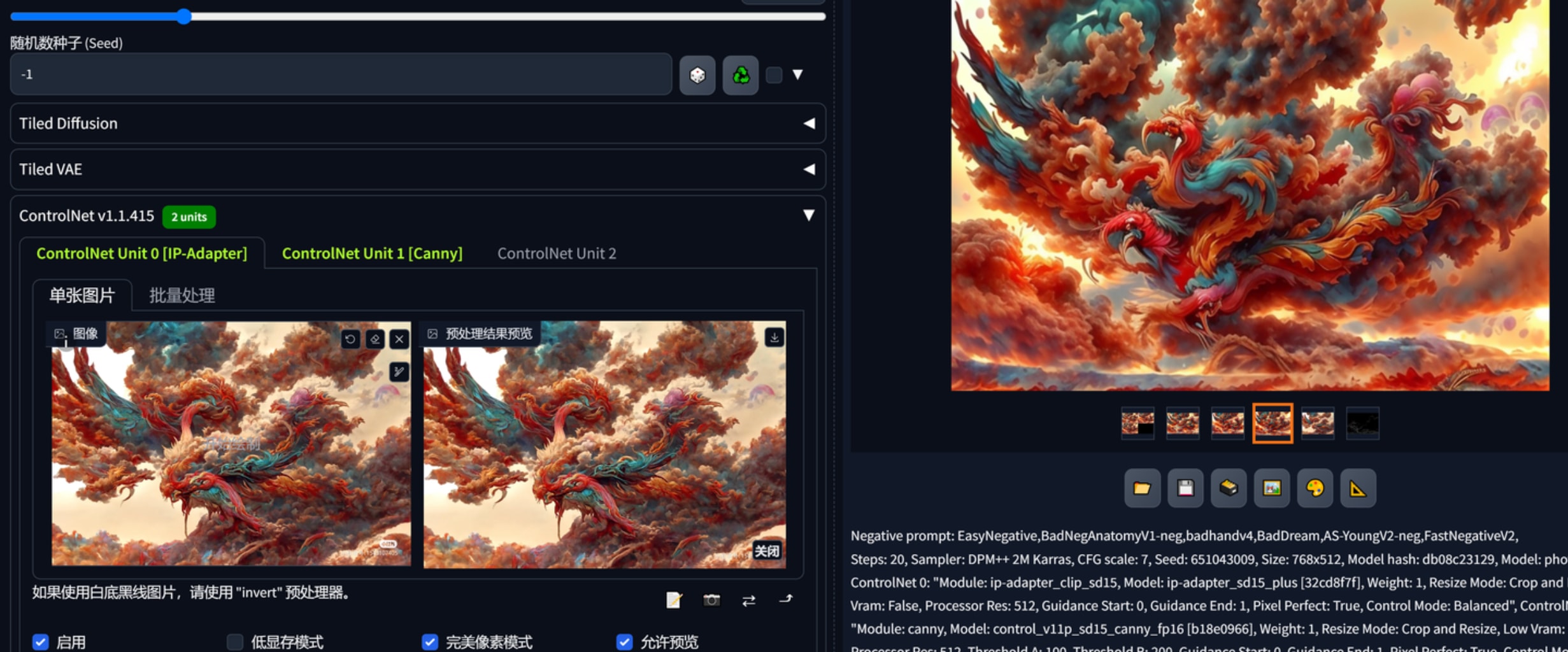
通过controlnet可以对限定提示词用预处理的约束来生成图片,比如下图中生成了多张马,其体态都是一样的,背景墙面的结构也被复刻。
不同的controlnet我暂时没有深刻体会在控制方面该如何选择,介入步数感觉影响不大,控制权重和控制模式确实有影响。
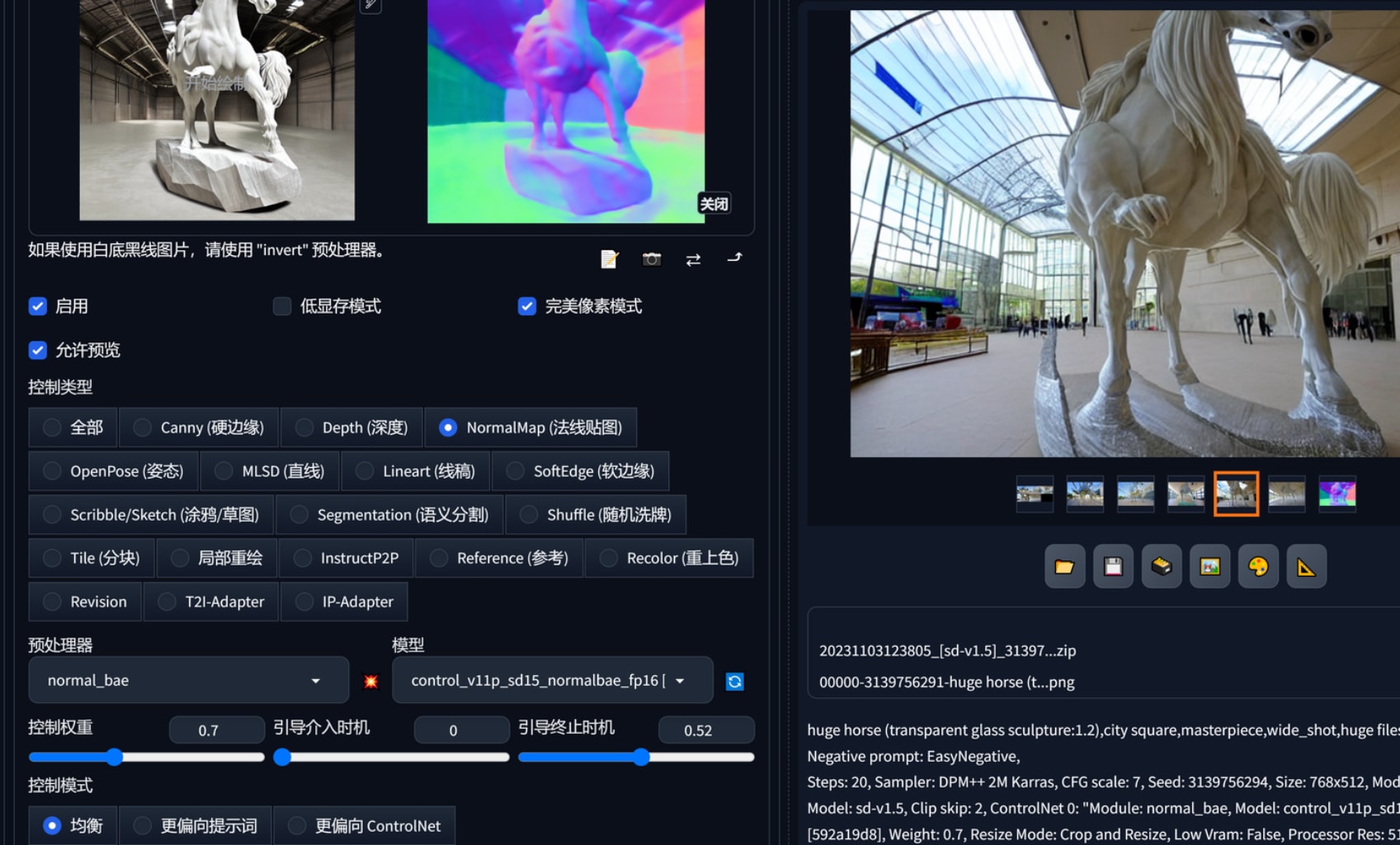
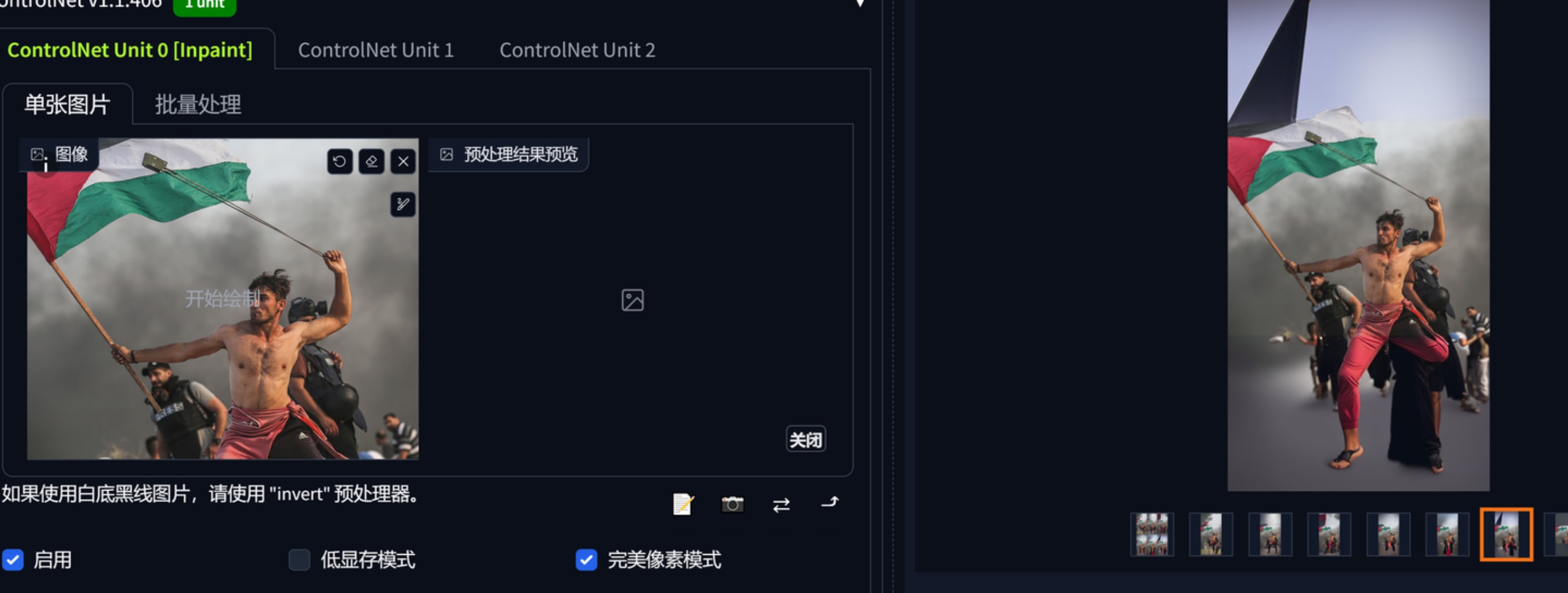
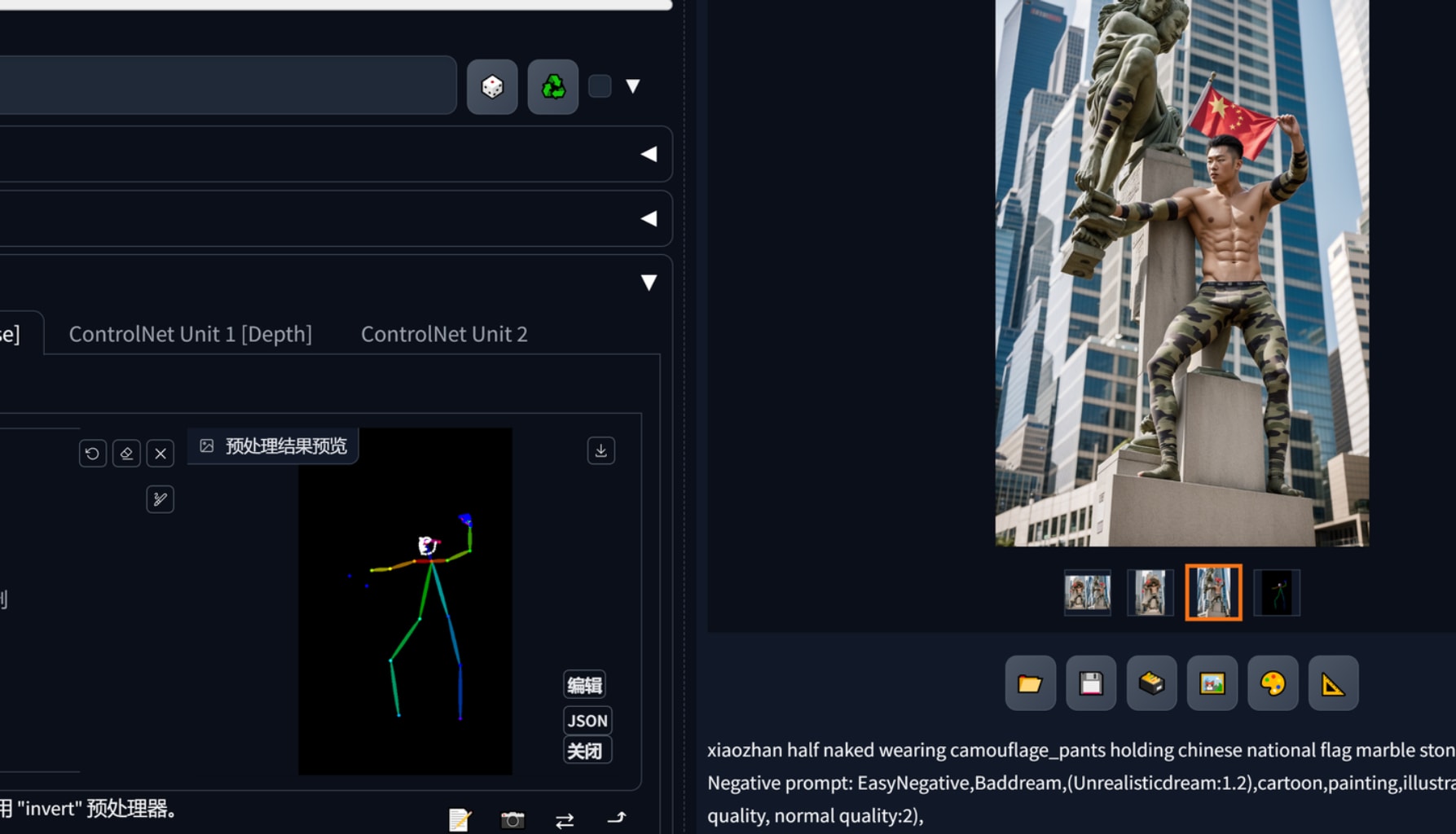
通过图生图可以把觉得不错的元素扩展,在controlnet中似乎无法对场景扩展.比如我想要这个巴勒斯坦青年投石索的动态,想要一个全身像,可以通过它扩展在利用controlnet openpose控制姿势。

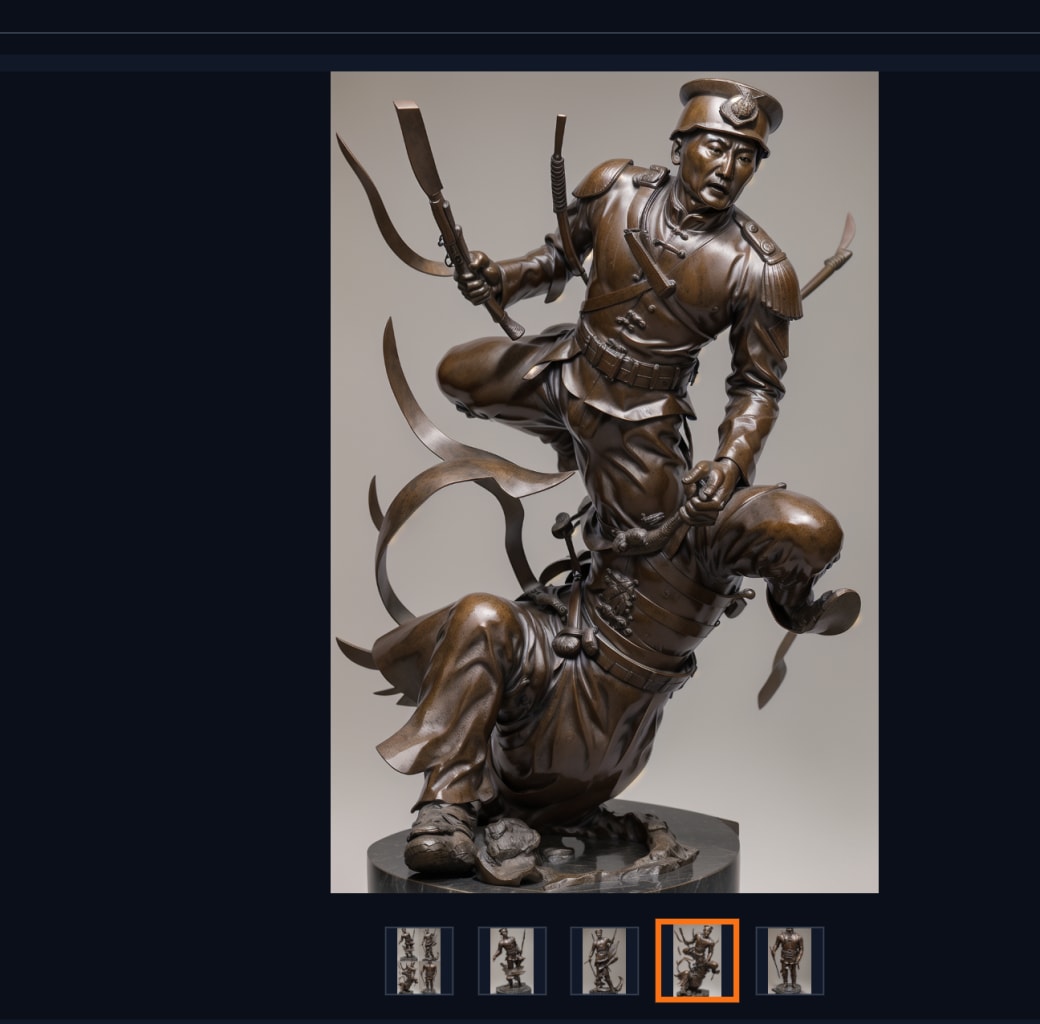
我发现用sd1.5、photon、realistic这几个大模型直接配合bronze sculpture lora出雕塑效果很诡异。
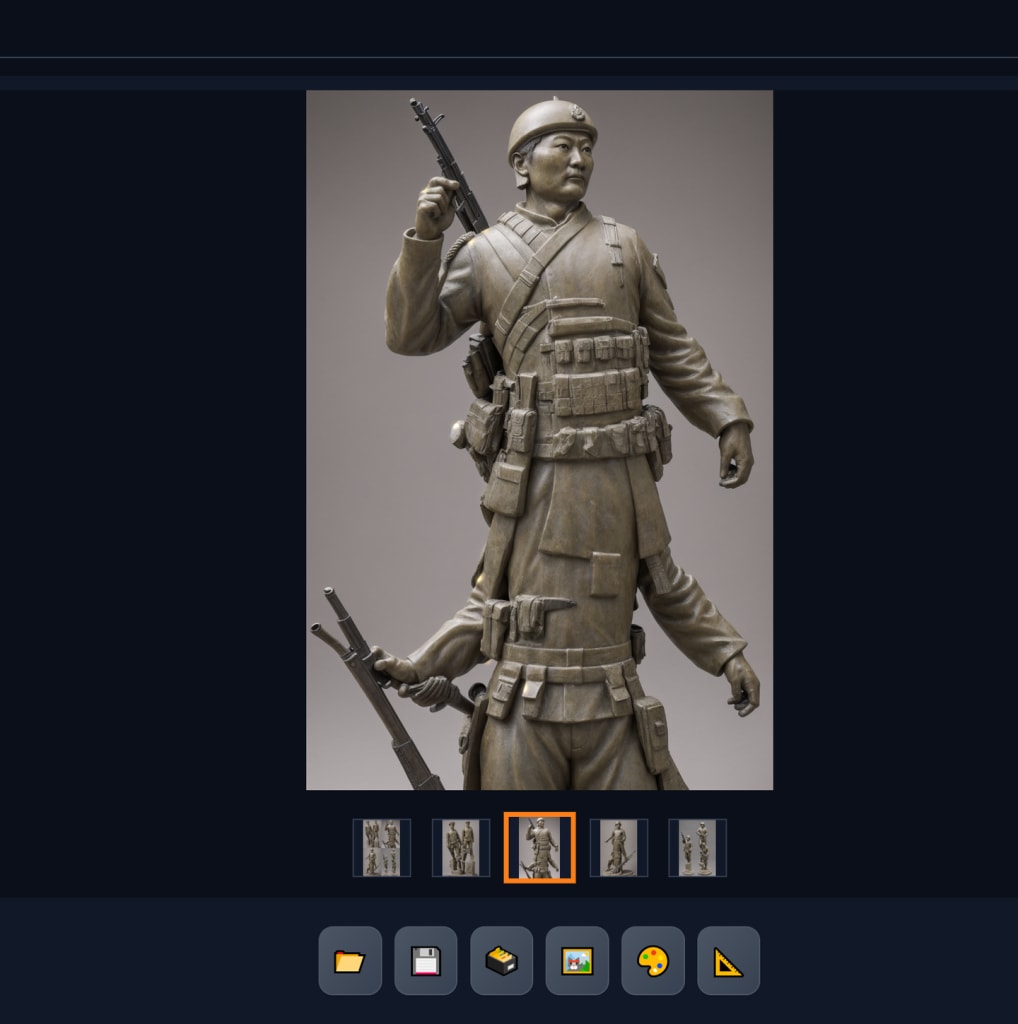
aarg用于生成建筑的大模型生成雕塑就更诡异了。

相对而言sdxl大模型生成的人物至少结构比例上是正常的。然而想要一个正常的asian、chinese脸却很难,我想换脸技术应该sd的社区有很多研究了,发现从roop到faceswaplab到reactor已经有好几种插件停更、迭代了,今天试着安装reactor有点麻烦,几十kb要5、6小时。

通过图生图,外国人看起来雕塑就“自然、和谐”了。


那么问题就变成了在转换雕塑前先要换脸,我试了下亚洲男性、acg武侠的lora都不理想。另外可以看出来旁边的那个矮柱装饰变得十分诡异,显然这需要局部重绘,相关的技术还得探索。

对于动物雕塑用photon配合bronze sculpture lora图生图重绘感觉效果很好。自此可以推论先用大模型a做出“原型”,再用图生图大模型b配合某lora或多个lora、controlnet精修,遮罩局部重绘一些细节以完成一个装饰部件的设计参考。
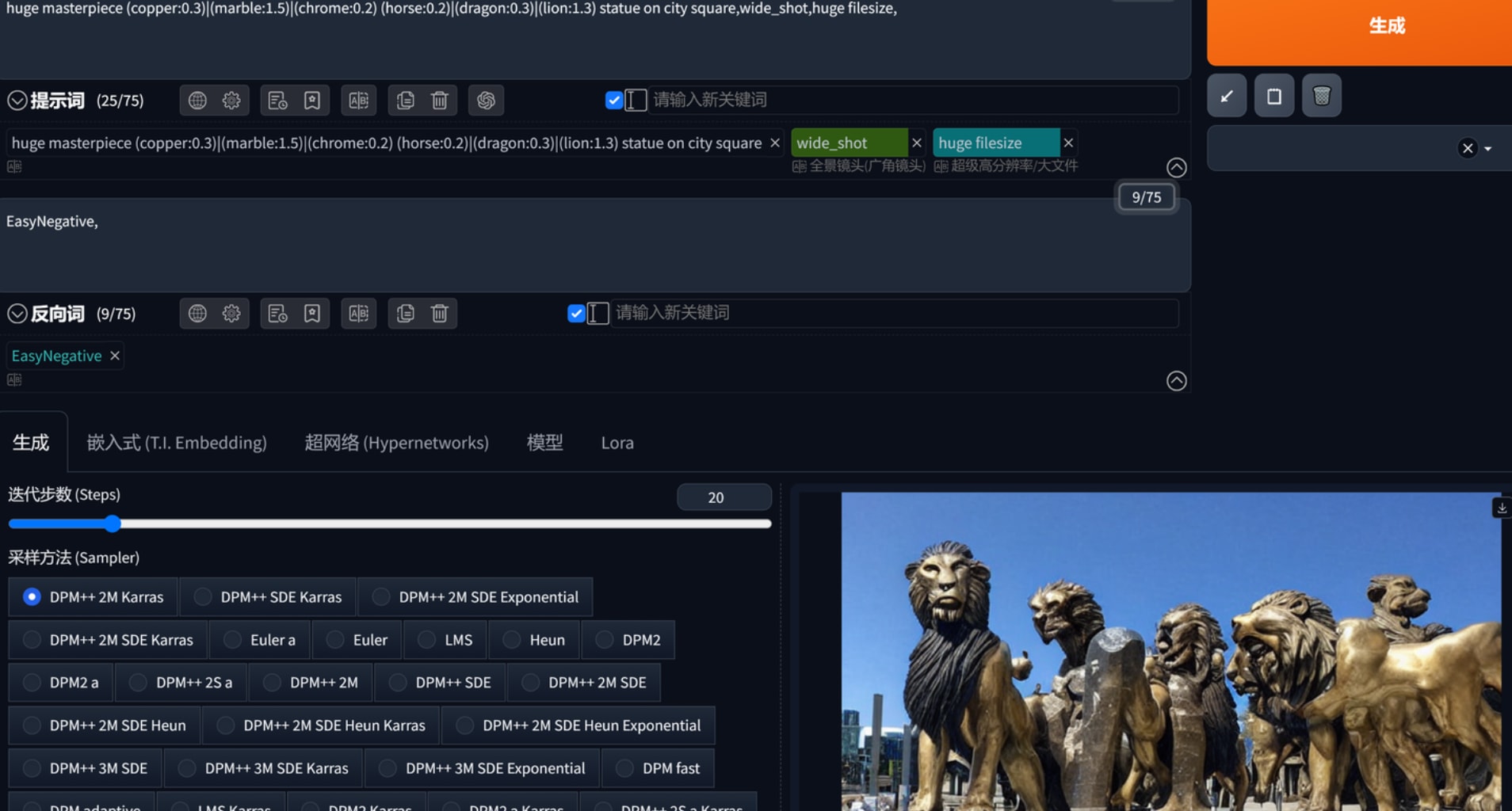
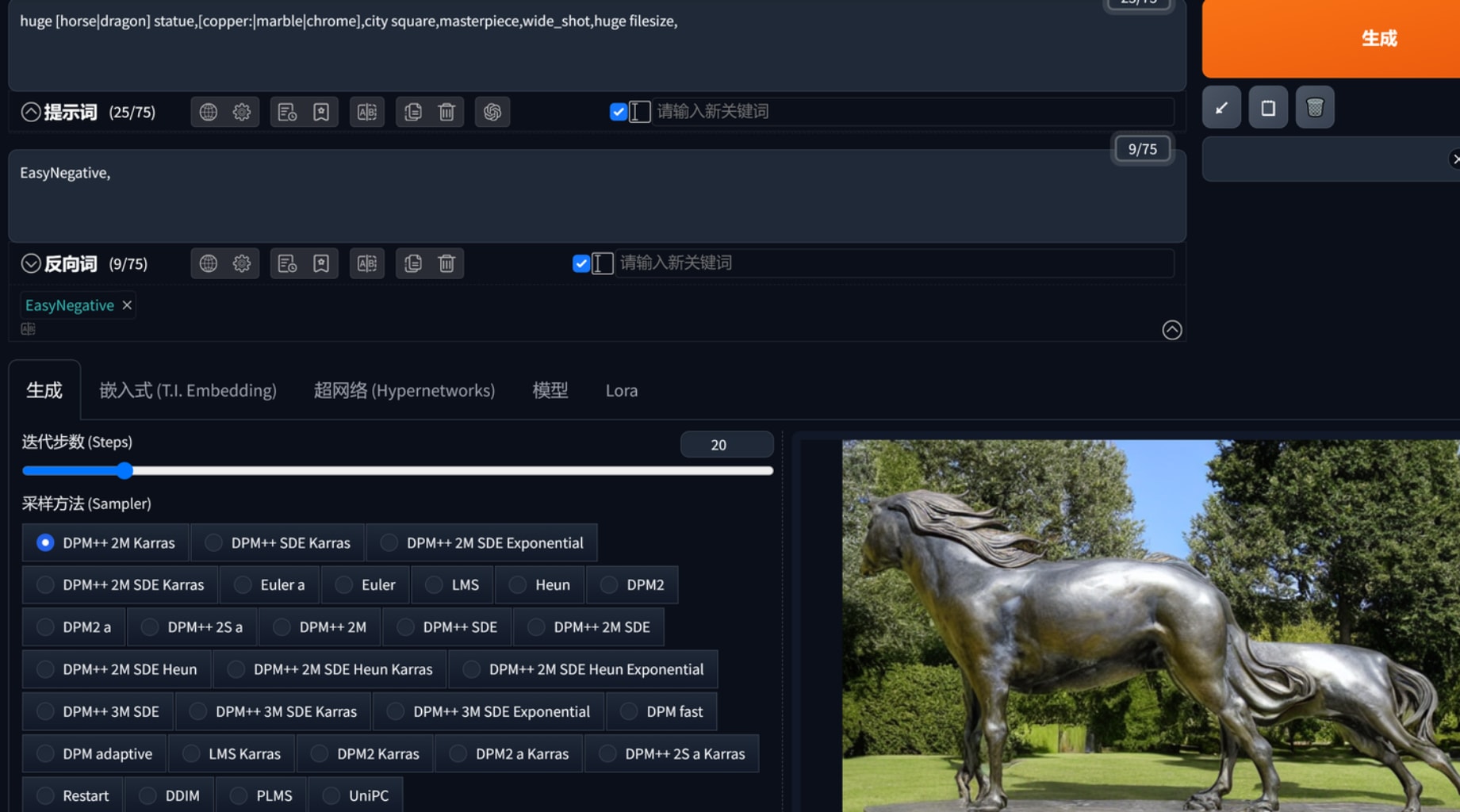
提示词注意事项,越靠前的东西决定了图片输出的“主体”,这可以从最初的步数看出来,”|”符号不同于”,”前者是同时生效。不过|的作用效果很诡异,我用huge masterpiece copper|marble|chrome horse|dragon|lion statue on city square,wide_shot,huge filesize,这串提示词以及red|blue|yellow clothes chinese boy working in ev factory发现真正同时生效的只有horse|dragon|lion


(tag:num)属于强调,然而即使marble提升到1.5仍然有copper为主导的图片产生,lion在1.3之后基本主导了雕塑内容。因此这个权重其实不确定性很大。
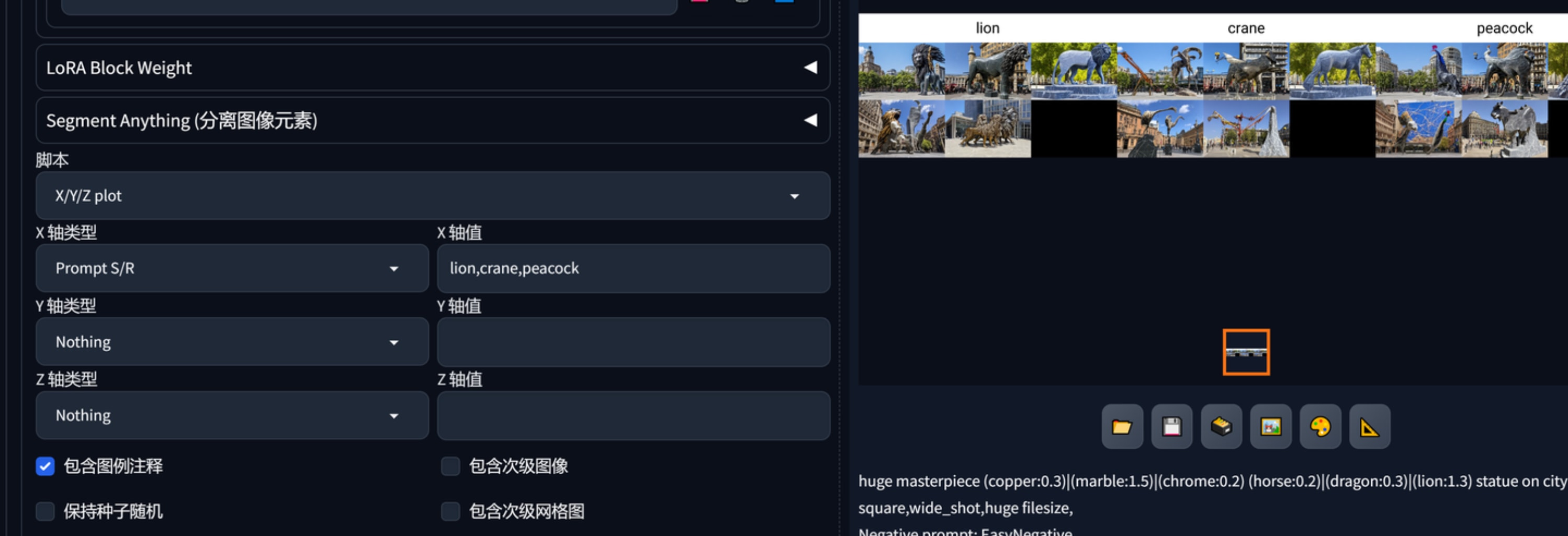
在脚本中用x/y/z plot可以替换提示词。
效果随着步数渐变,我暂时想不出来有什么应用场景。



不过这种混合在材质上不好实现。
photon、absoluterealistic、cyberealistic在生成人物时,结构往往不正确,sdxl比较合适做基本人物原型。这里要提一下使用sdxl大模型时vae要选sdxl_vae_fp16fix.safetensors,不然会出现报错无法运行。


对一个指定图片改背景没法用文生图,只能图生图,那么就涉及人物和背景的划分了,这一周接触stable diffusion比较混乱,主要是自己不知道想去实现什么,导致了随波逐流,网上的教学成千上万看不完的,但是具体到自己的应用又不知道如何入手,初期肯定有个软件上手的过程。目前我的应用场景有:
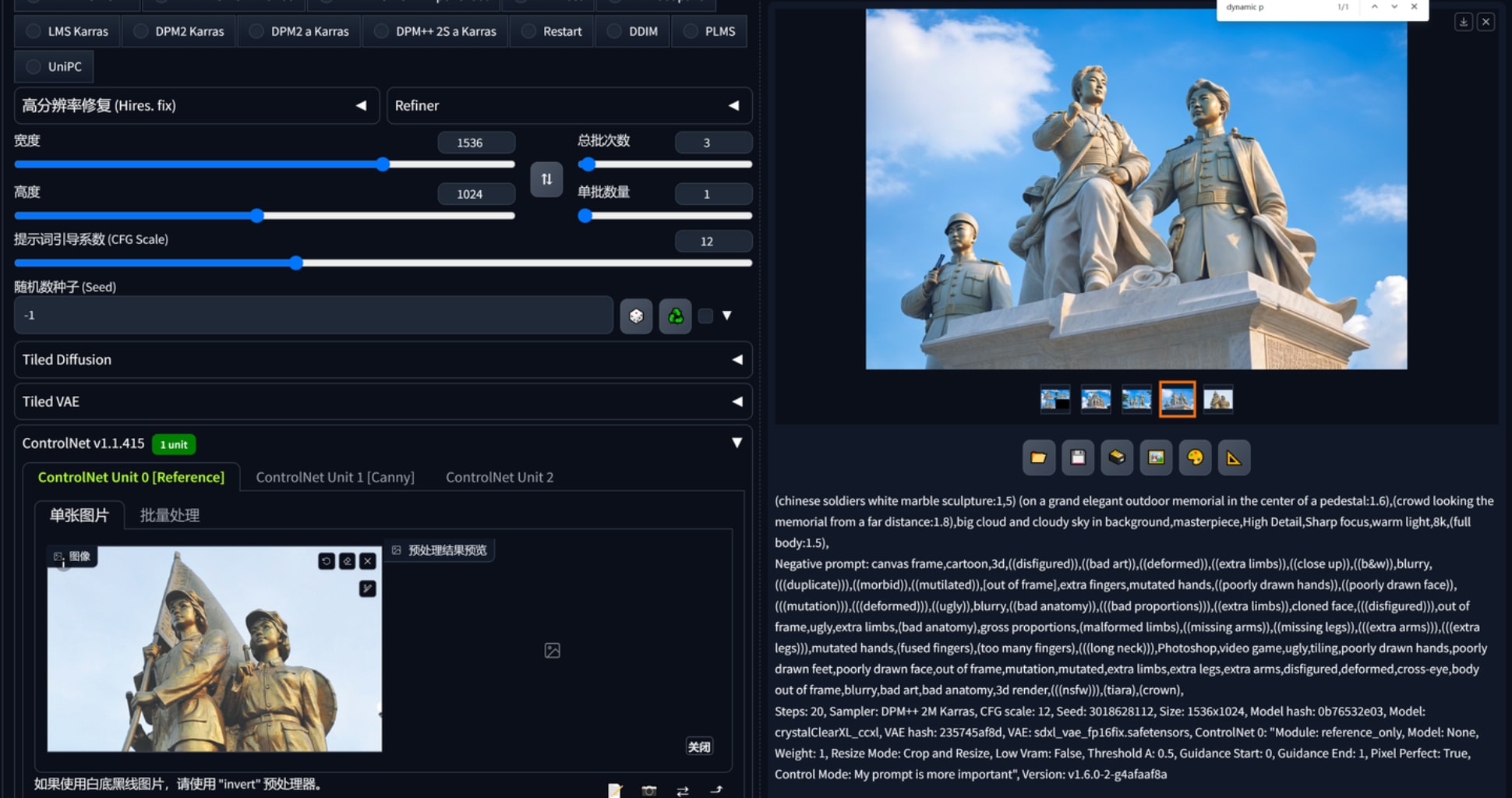
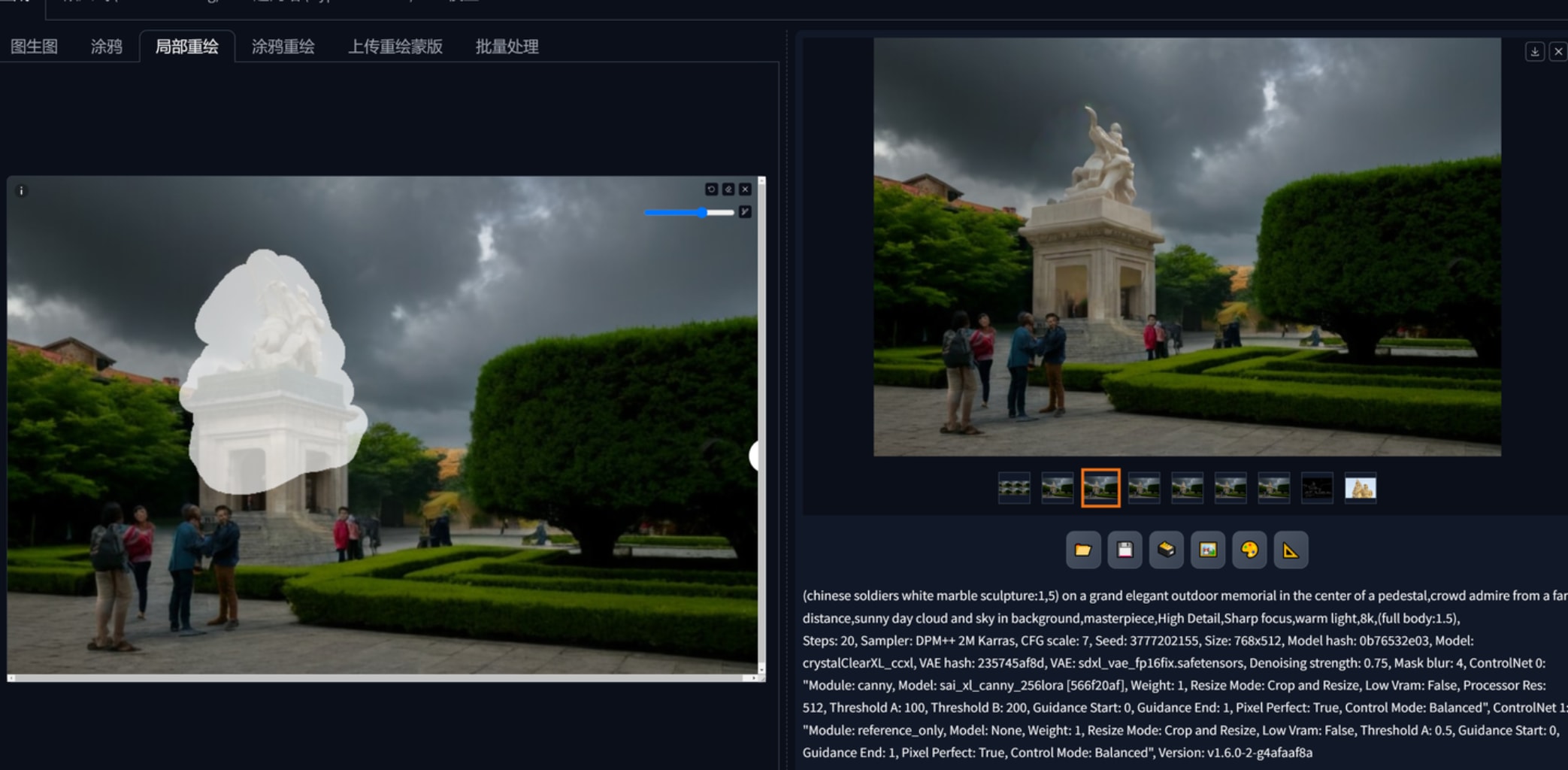
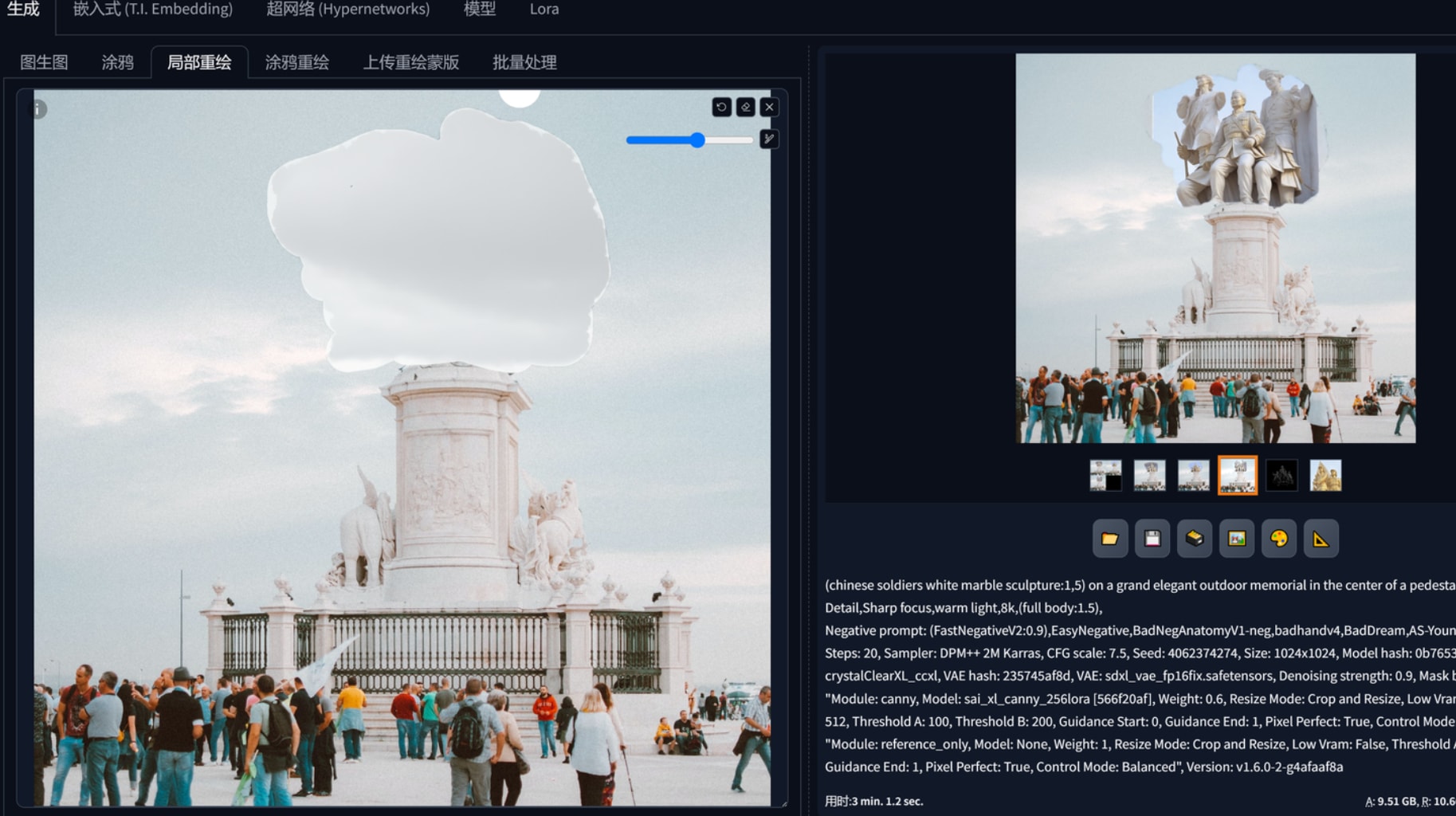
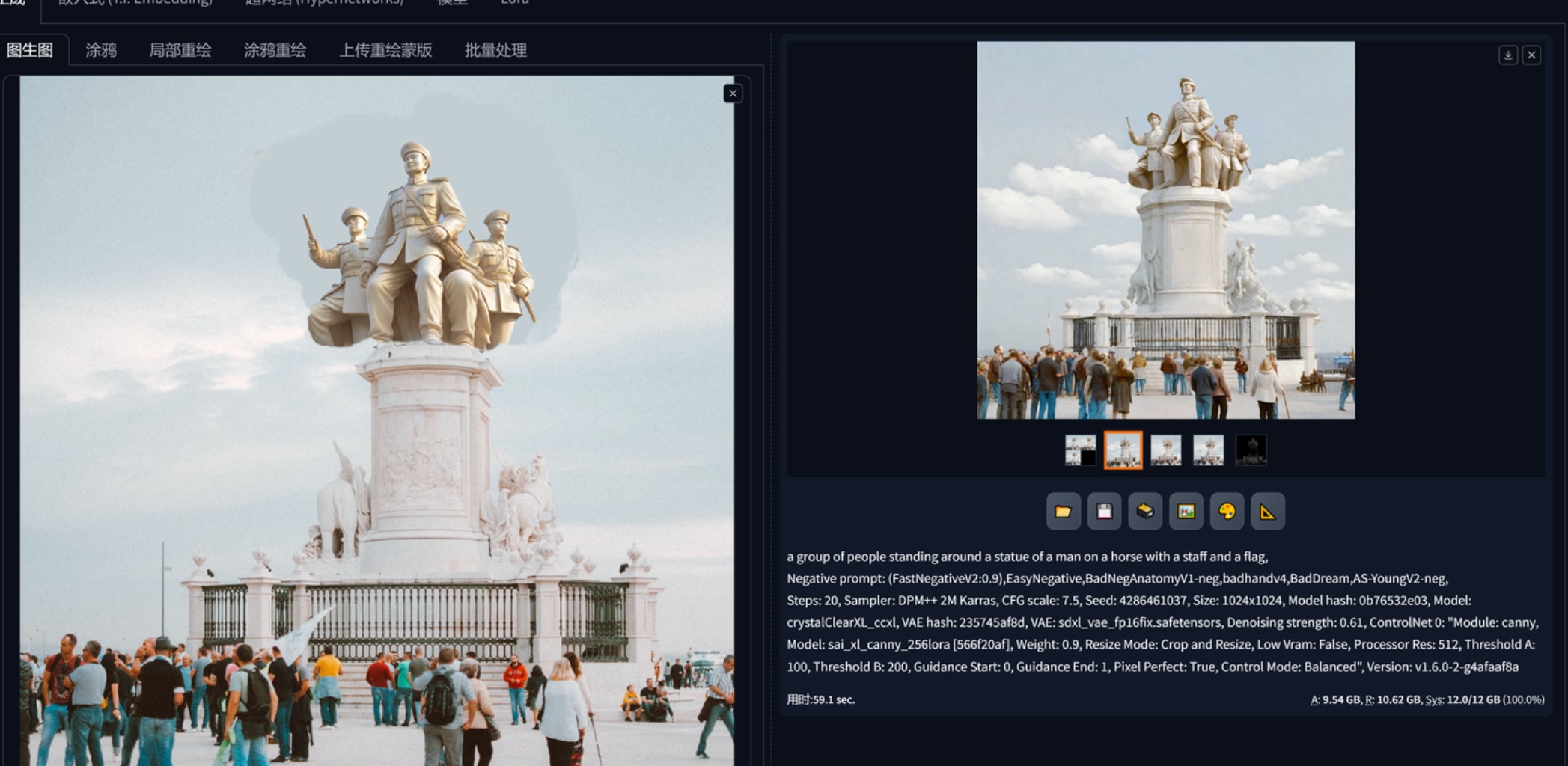
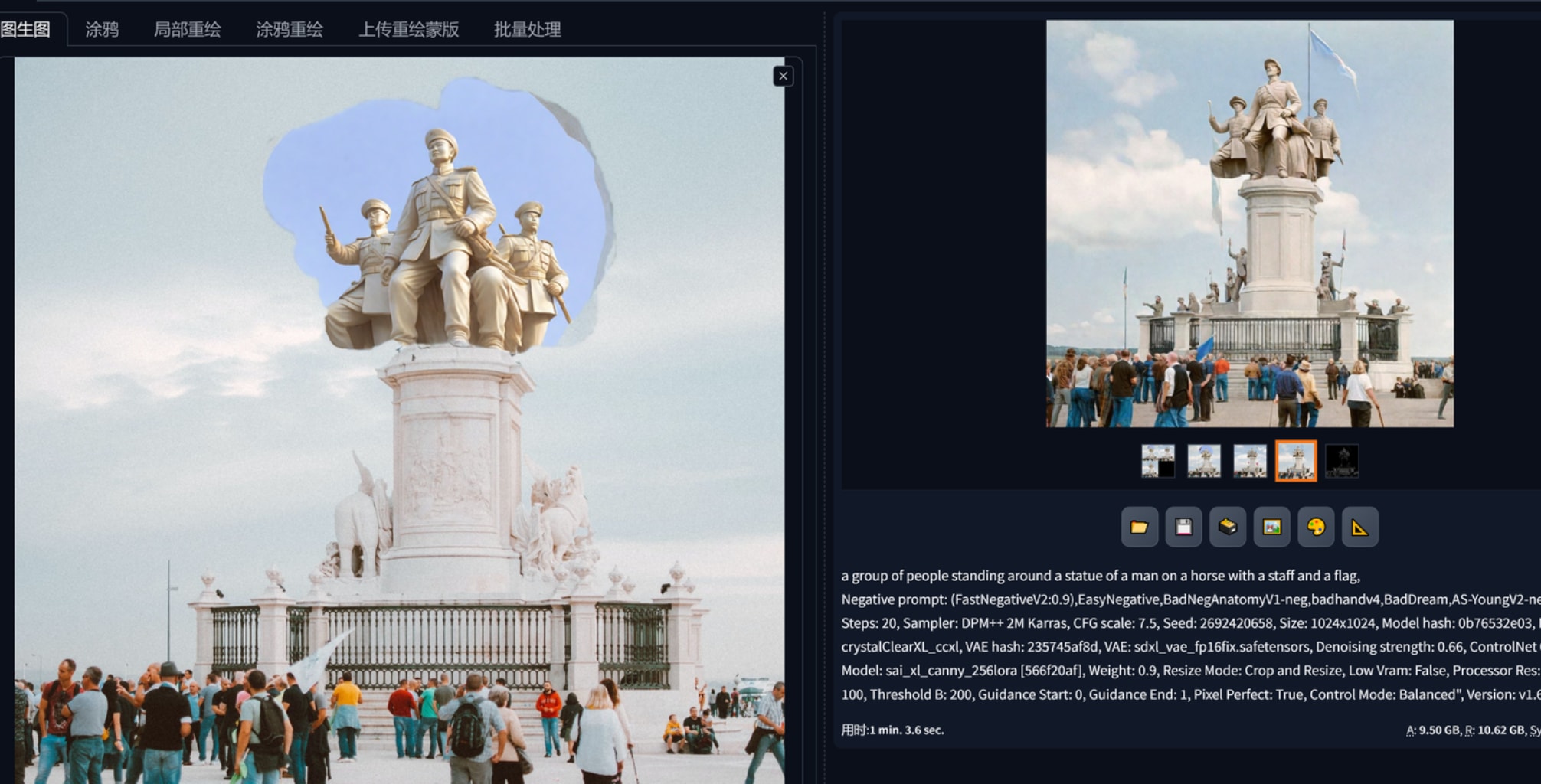
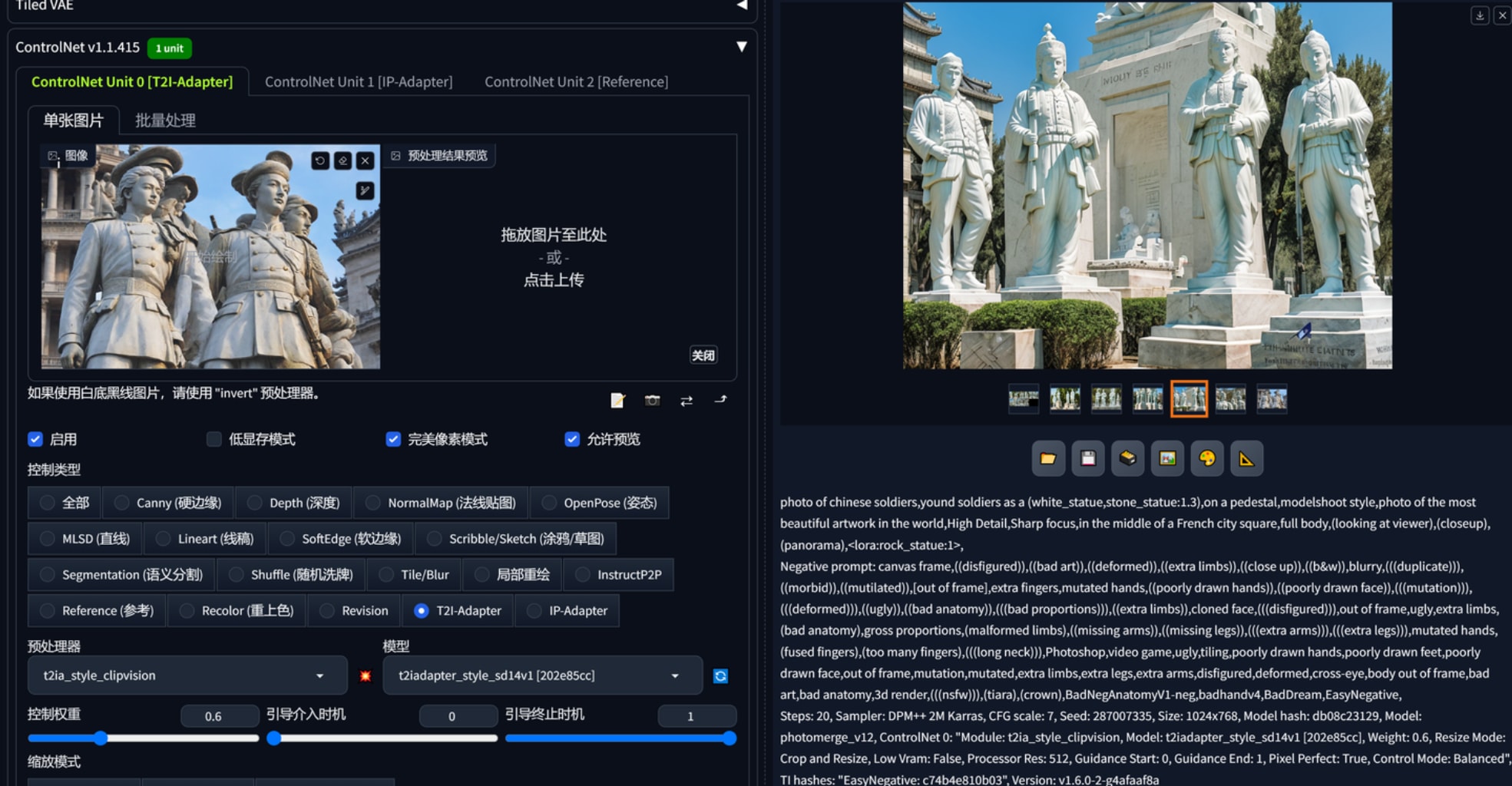
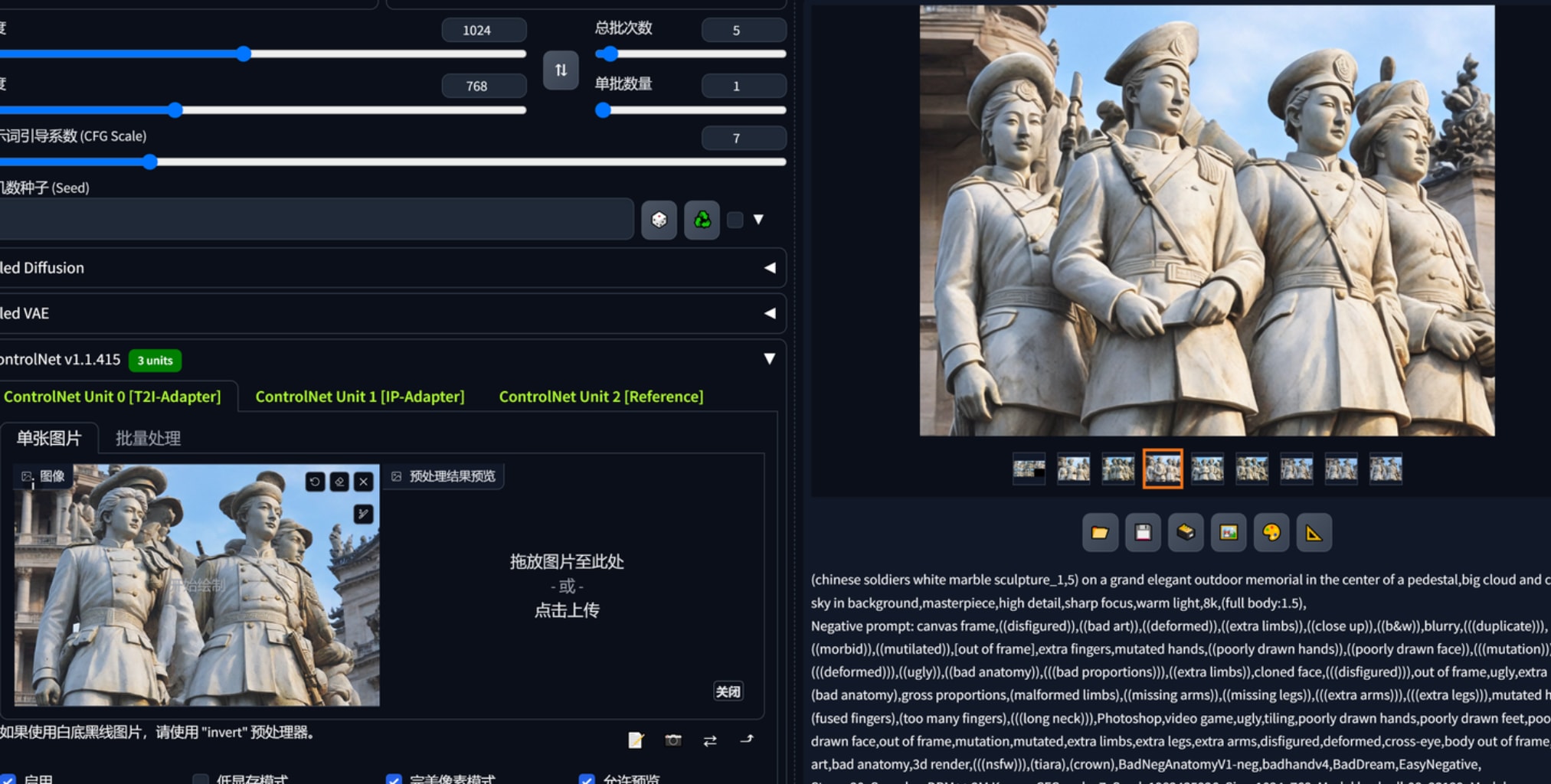
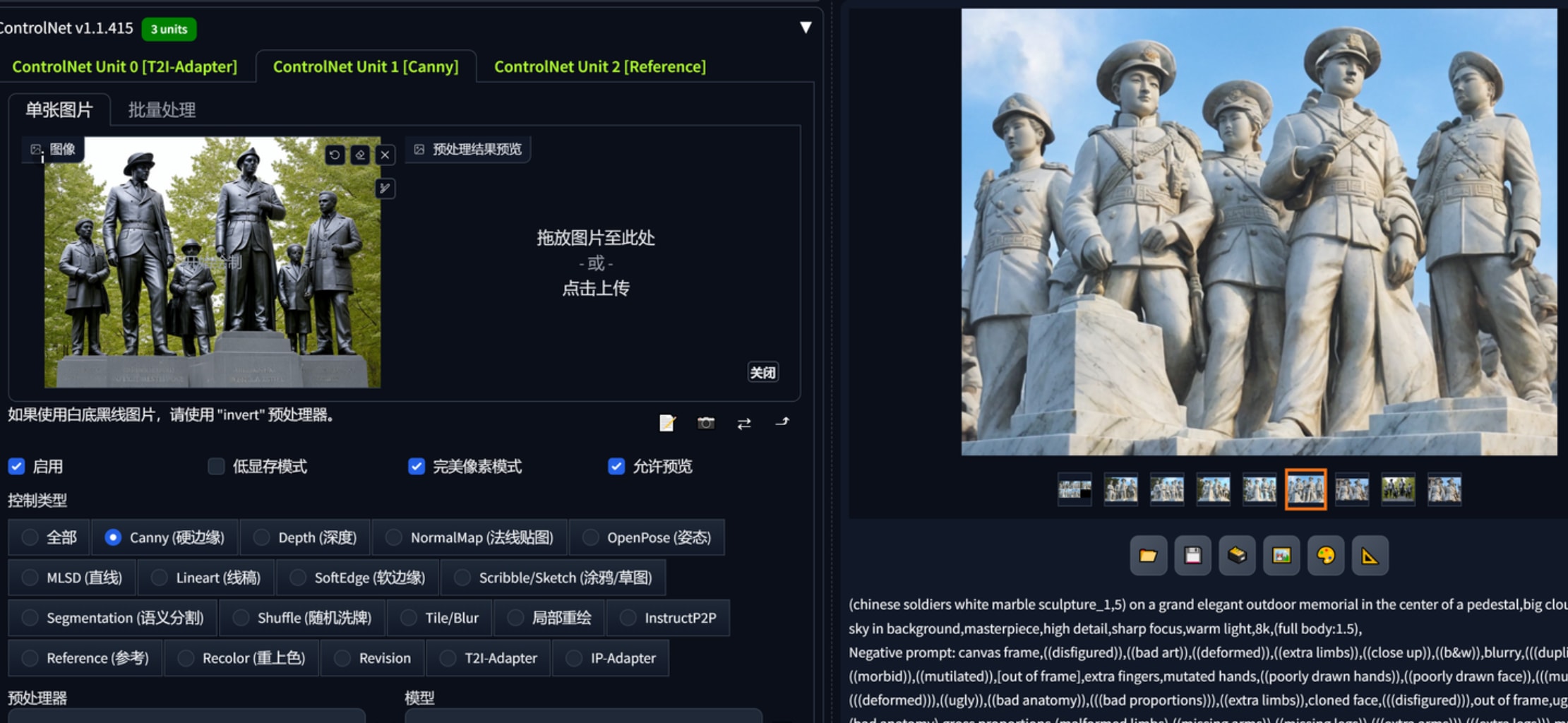
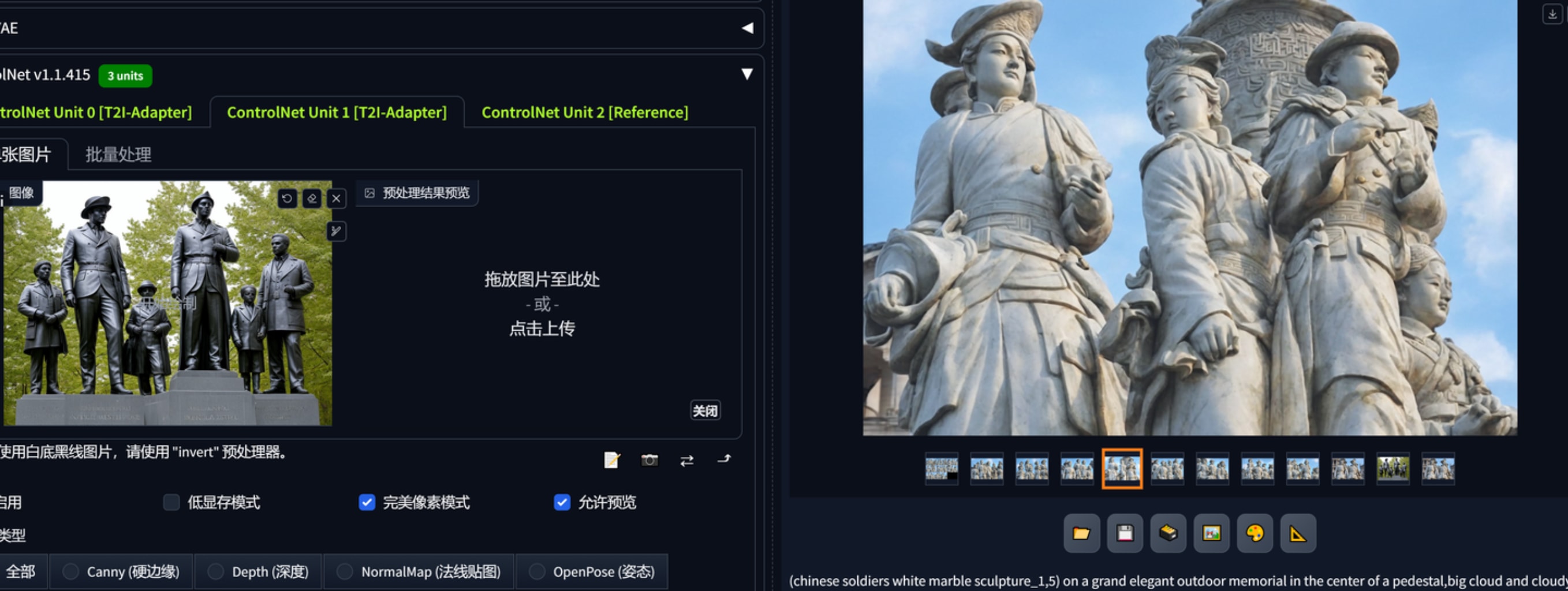
1.文生图,配合合适的大模型、lora出一些设计概念,controlnet reference “作用力”蛮强的,想要生产同一画风的平面布局可以用这个。下图2、3、4、5是基于红色娘子军这个雕塑作品生产的,可以看到一开始连材质都十分近似,构图方面都仿照了半身,以至于偏向提示词、给加权重都很难改它的风格。这里还要再提一下凡是基于sdxl的大模型,vae都要勾选,不然出图会报错。768x512三张图用sdxl是1分40秒,1024x1536是4分20秒。reference这个controlnet会根据参考图本身的大小影响输出的速度,红色娘子军160kb的图用了4分钟左右出3张1024x1536而1.67mb的参考图则会导致需要30多分钟出图,因此reference给的图注意先压缩大小。

(chinese soldiers white marble sculpture:1,5) on a grand elegant outdoor memorial in the center of a pedestal,crowd admire from a far distance,sunny day cloud and sky in background,masterpiece,High Detail,Sharp focus,warm light,8k,(full body:1.5),




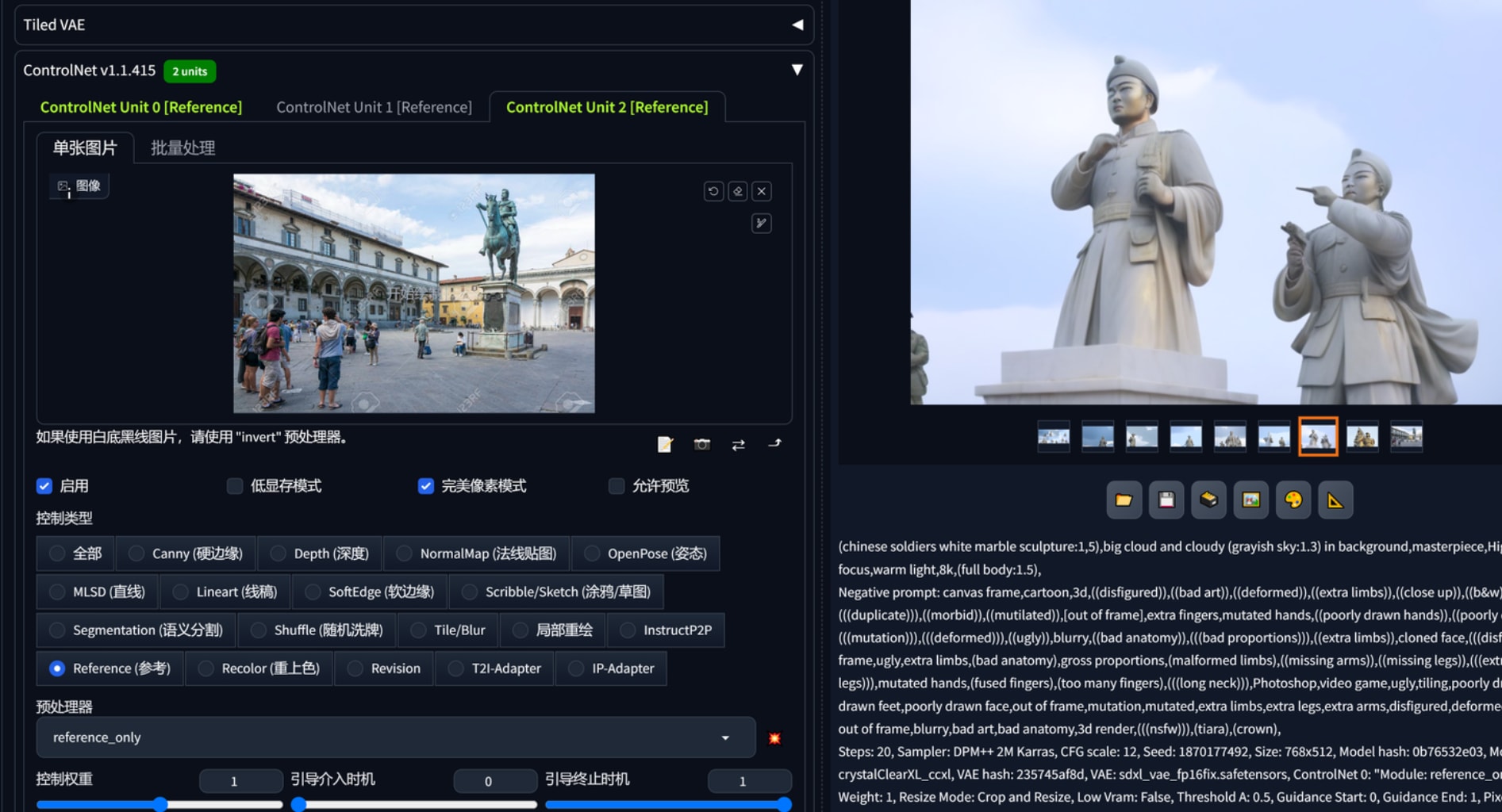
那么有没有办法结合两个甚至更多个reference呢?我试了下难以达成想要的效果,在两个reference的作用下,雕塑的质量大大下降,人体结构变得含糊不清。

仅有一个参考图时,提示词和原图风格偏离较大的情况下得不到理想效果。
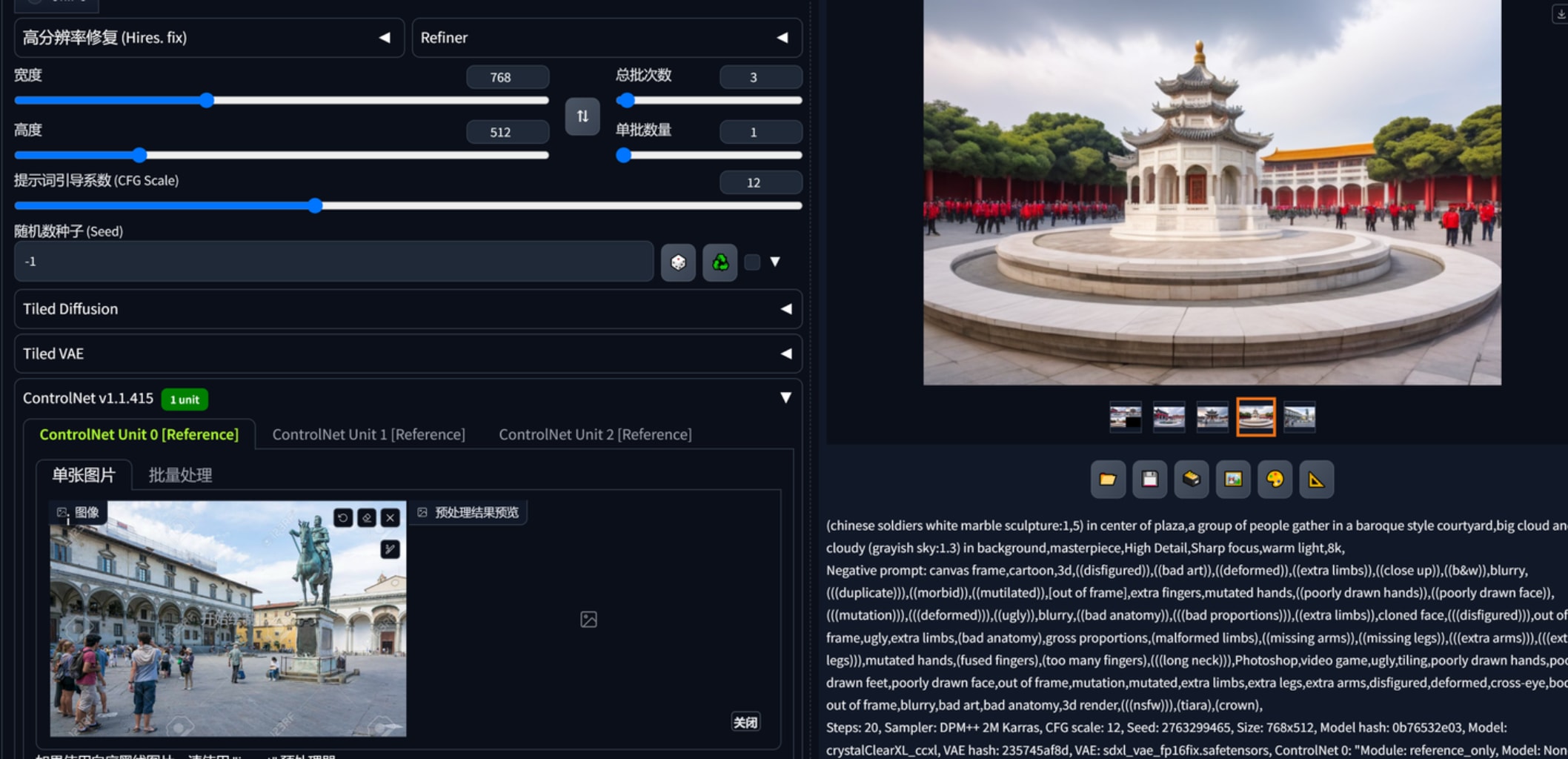
修改提示词为反推,这下可以得出靠谱的同类设计概念了
尝试图生图,蒙版局部修改,用controlnet openpose、reference、canny都不行。
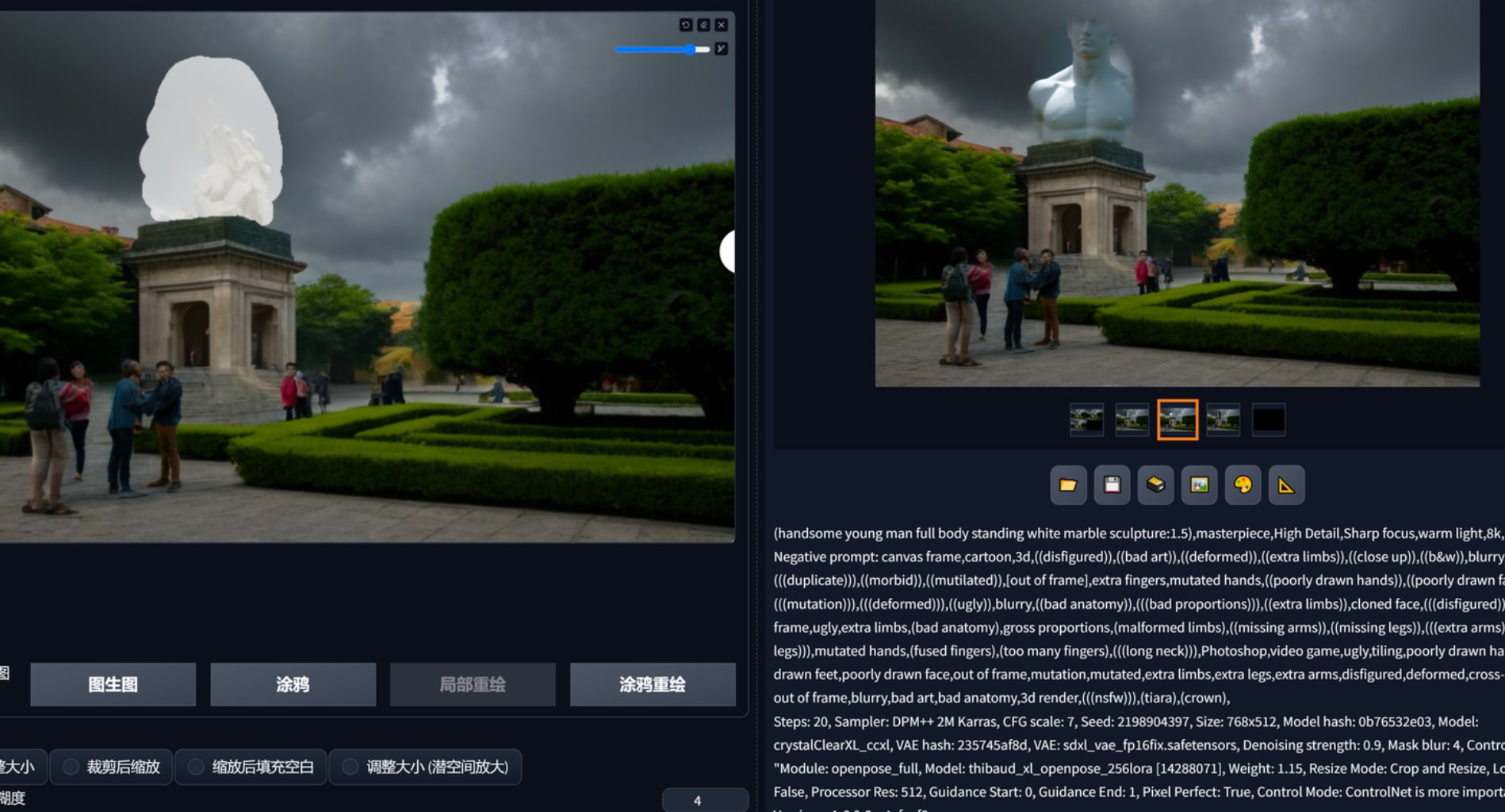
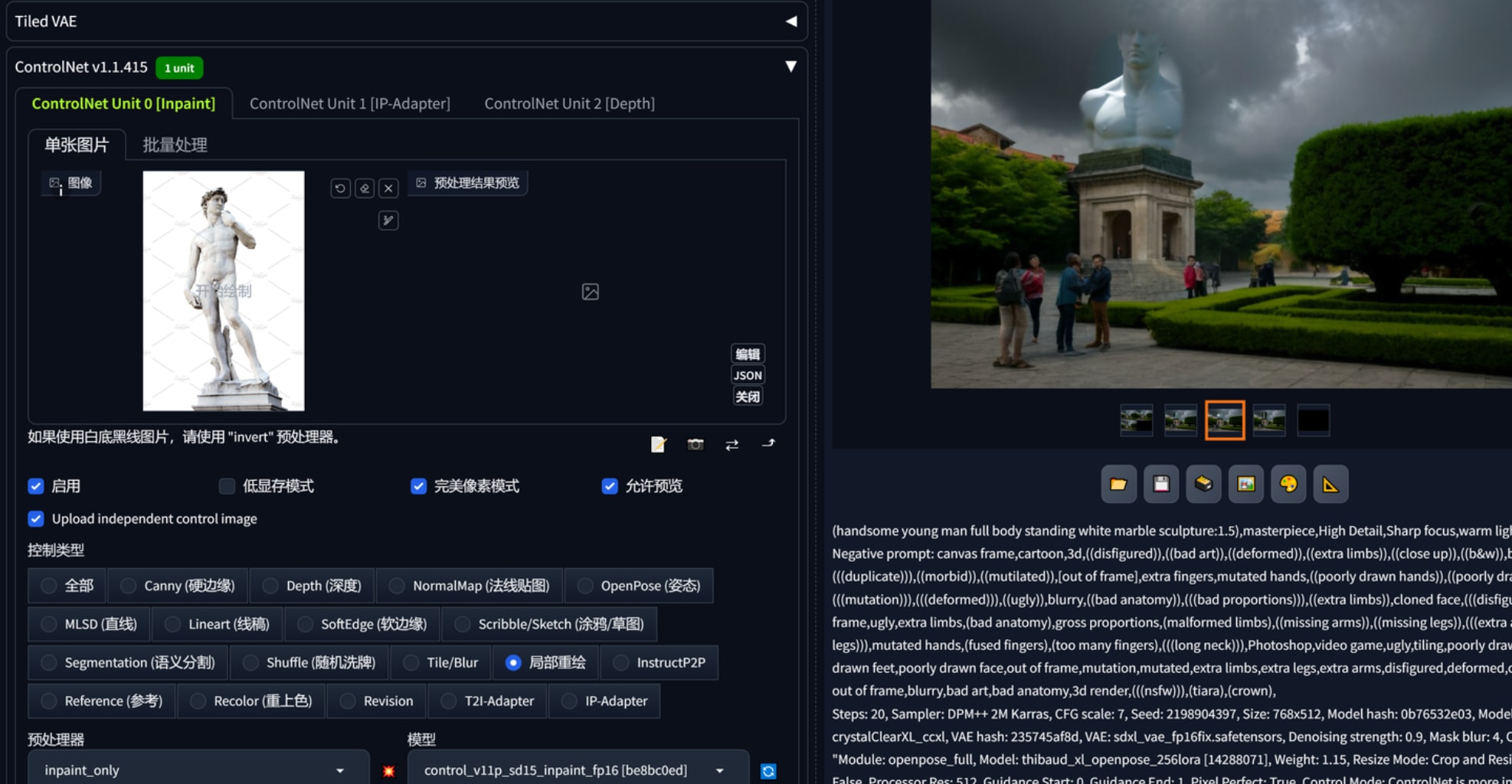
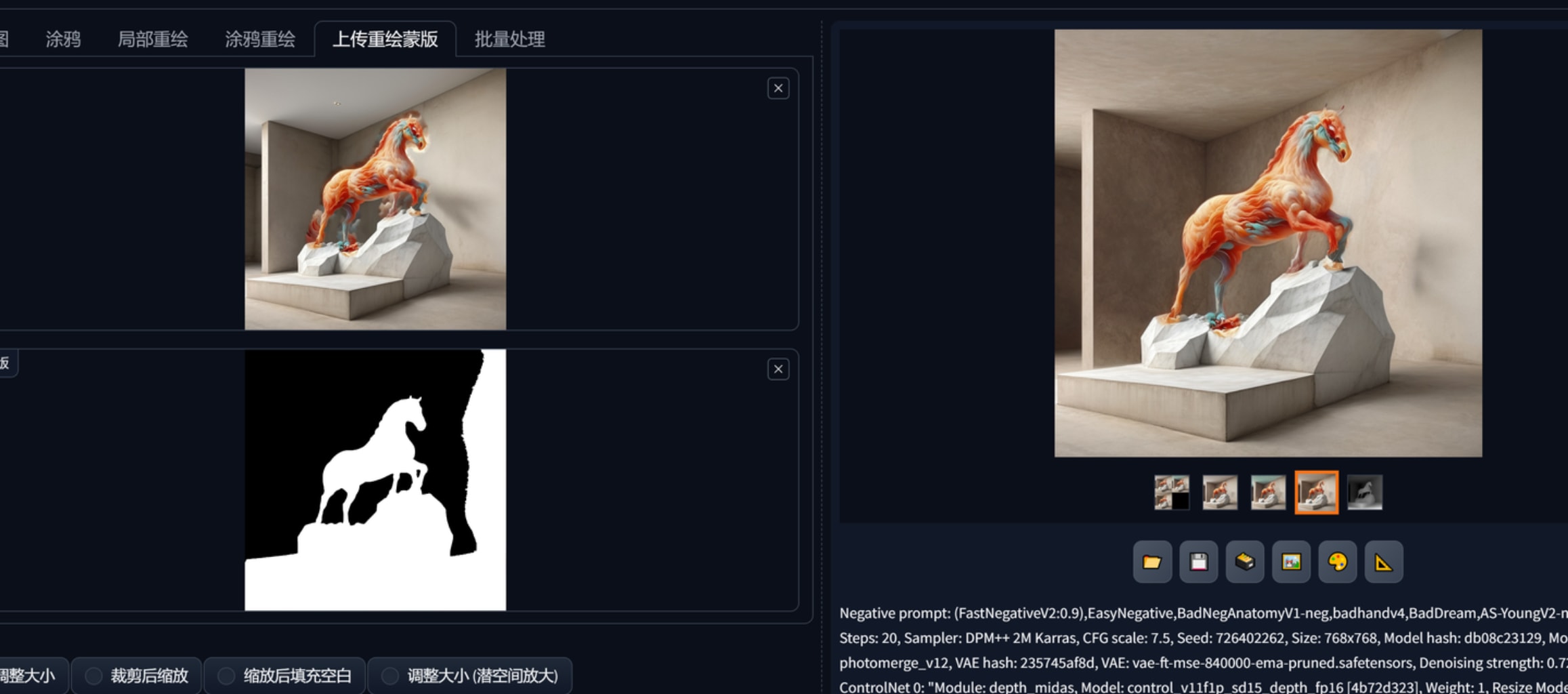
截至2023.11.6,网上的指定换脸、换装都有十分特殊的处理方式,我尚未看到一个教学能用重绘蒙版添加指定风格的东西。那么思路就是指定风格的东西额外生成ps摆进去以后再用重绘修复不和谐?可以确定重绘只能生成非指定的和整个画面契合的东西,利用重绘修复外部导入的指定“部件”并不可行。重绘开小了搞不定接缝,开大了整体诡异与原画完全脱节了。


如果串联起两步把之前文生图生产的“部件”放到图生图生产蒙版区域可以较好融合,但是图片本身尺寸小,像素低就没法解决“部件”的艺术性。
先对原图清除要替换部件的地方,比如这个例子中要替换雕像,那么涂抹雕像位置重绘,提示词用天空随便搞个天空,我觉得空白也行,直接ps里面挖掉填充白色,再把需要的部件在ps中摆放到合理的位置,把添加好部件的图作为canny controlnet控制场景的结构分布,然后clip反推的提示词作为限制,可以将想要的部件替换原有的东西。注意重绘幅度大概在0.65的样子可以消除背景与部件衔接和光感的不和谐。这样一个流程下来实现了对场景装饰的细化处理,

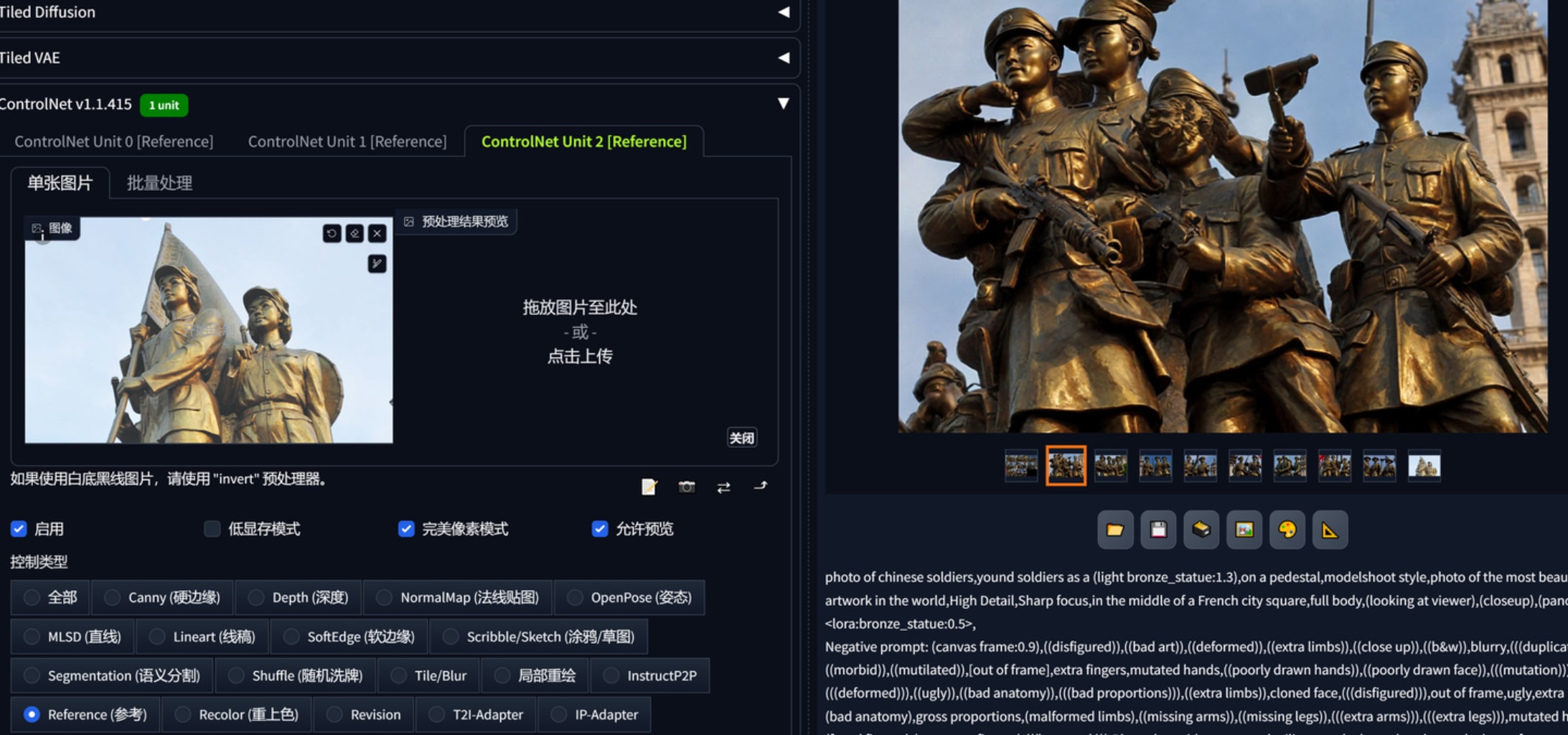
2.对某种部件上材质,这里使用crystalClearXL_ccxl.safetensors,1536x1024 8张用了12分钟出图。可以看到人物和动物被完全转化了铜材质,这是通过lora达到的




水晶材质的lora
realistic full body glass sculpture of bnycstm alisabcnv,transparent,translucent,1beautiful big eyes chinese girl gently smiling,reflections,(art gallery interior background:1.5),(warm lighting:1.5),illustration by Greg rutkowski,yoji shinkawa,4k,concept art,lora:sdxl_glass:1.3,

white transparent (lion glass sculpture:1.3),reflections,crowd people in big art gallery interior background,(warm lighting:1.1),masterpiece,High Detail,Sharp focus,(in the middle of a booth:1.2),8k,masterpiece,



经过不断地尝试,在我看来lora可以概括为添加一种大众角度视觉上可明辨的风格。比如说某种材质、某种服装、某个明星脸、某个动漫人物、某种室内设计风格、某种上色,色彩风格等等。
大理石材质
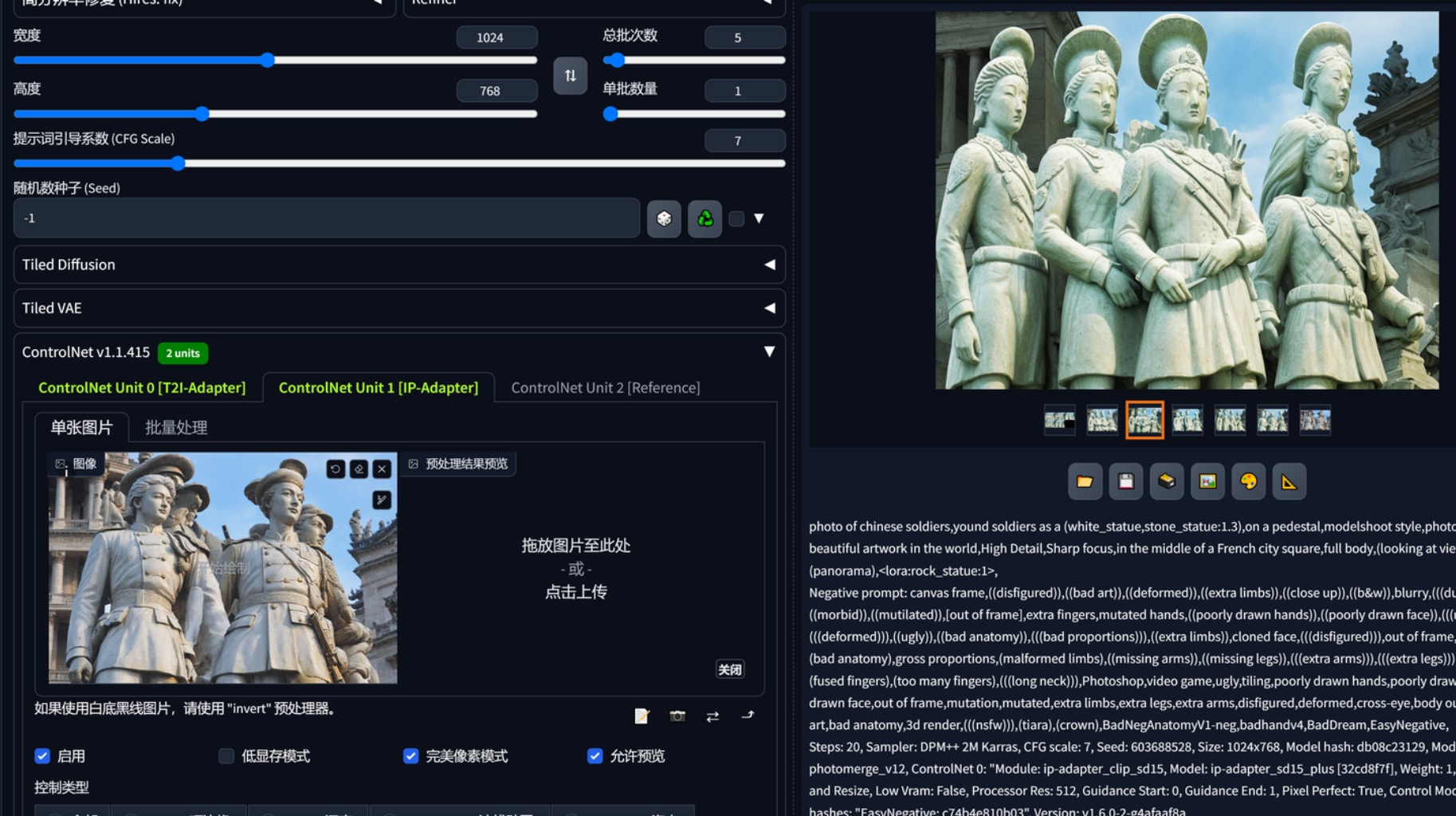
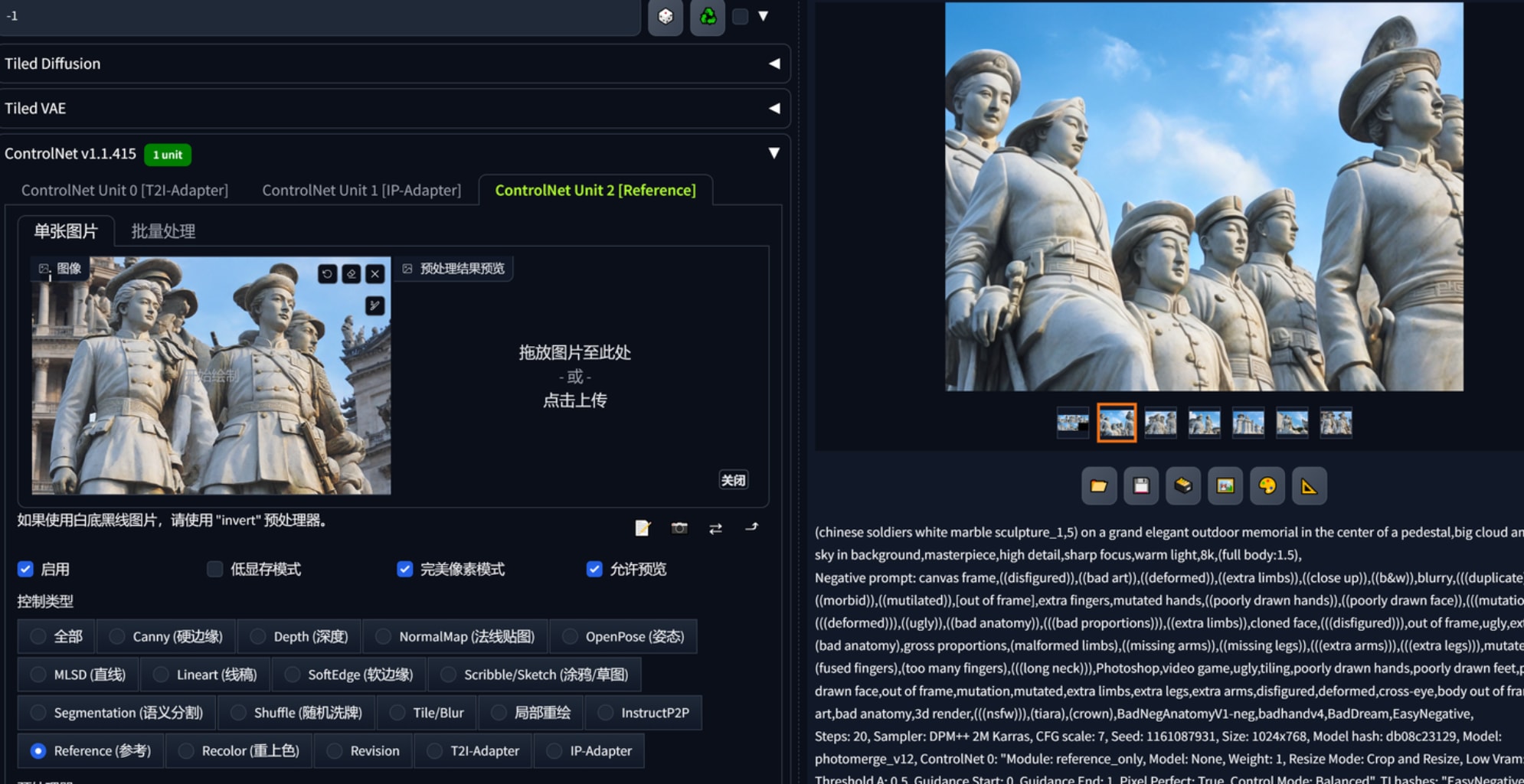
photo of chinese soldiers,yound soldiers as a (white_statue,stone_statue:1.3),on a pedestal,modelshoot style,photo of the most beautiful artwork in the world,High Detail,Sharp focus,in the middle of a French city square,full body,(looking at viewer),(closeup),(panorama),lora:rock_statue:1,

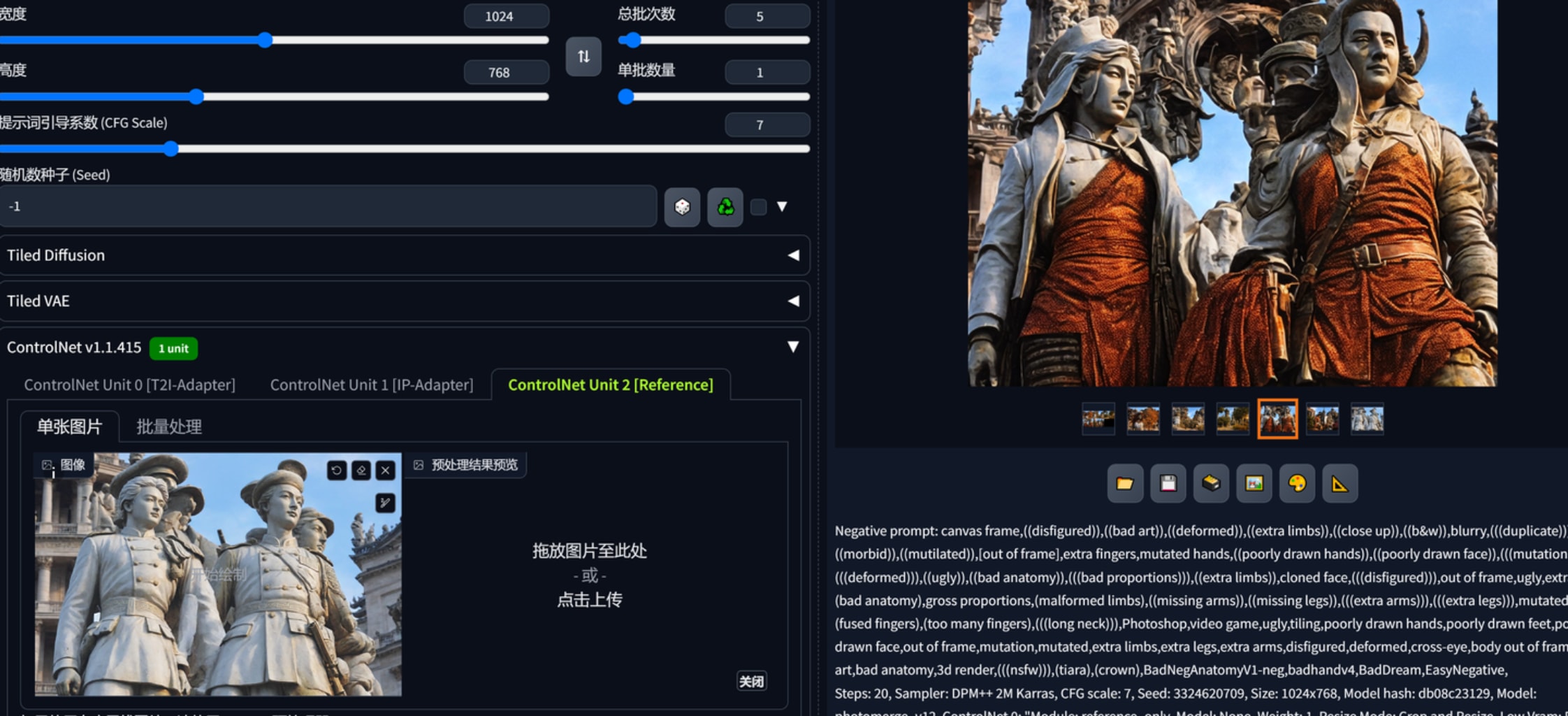
3.对某种复杂的“风格”、“装饰”迁移。在小红书看到一种云和龙凤结合的手法,假设这是一种我们需要的装饰,怎样生产变种?在这个案例中用提示词加controlnet reference生成的结果完全偏离,我推测reference无法还原过度抽象的东西,使用ip-adapter加canny结合到一个云状的照片后成功复现了这种效果。用局部重绘和controlnet canny把这种“风格”、“装饰”添加到一个指定物体上,再用蒙版重绘去除衔接问题。注意ip-adapter不能用sdxl的,至少这个云凤、云龙的风格装饰上无法迁移。



4.ip-adapter、t2Iadapter、shuffle组合生产近似“风格”
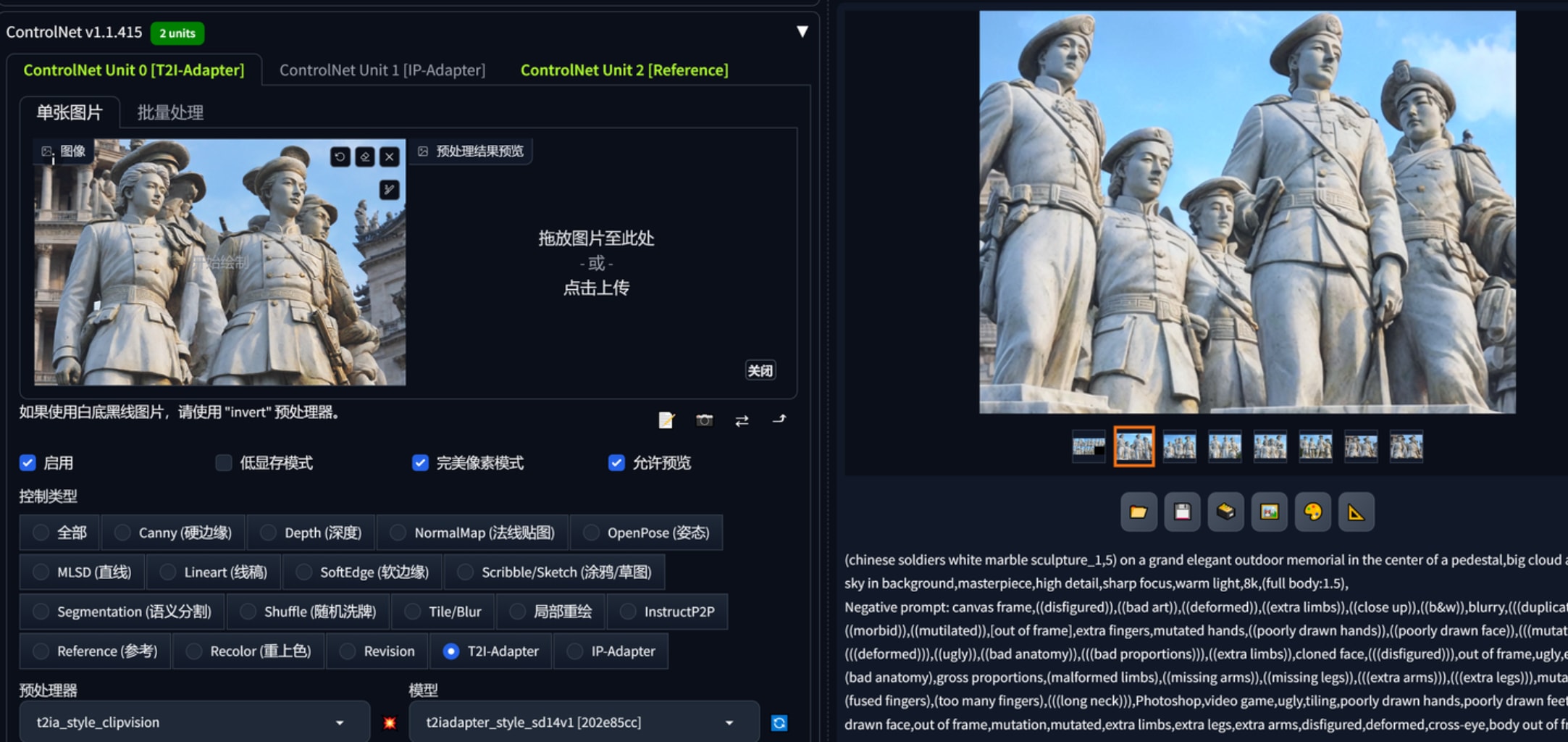
以下为无提示词用t2Iadapter生产的图。
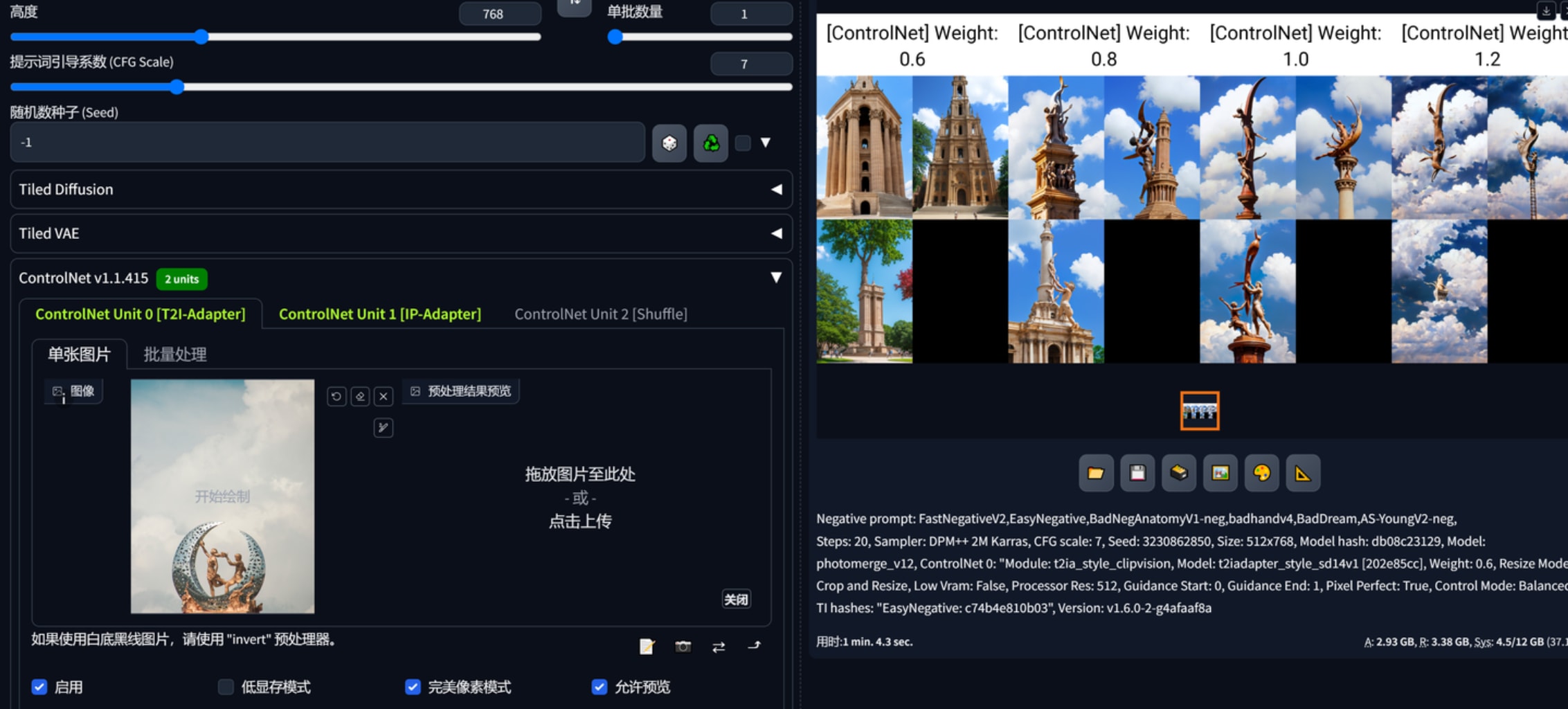
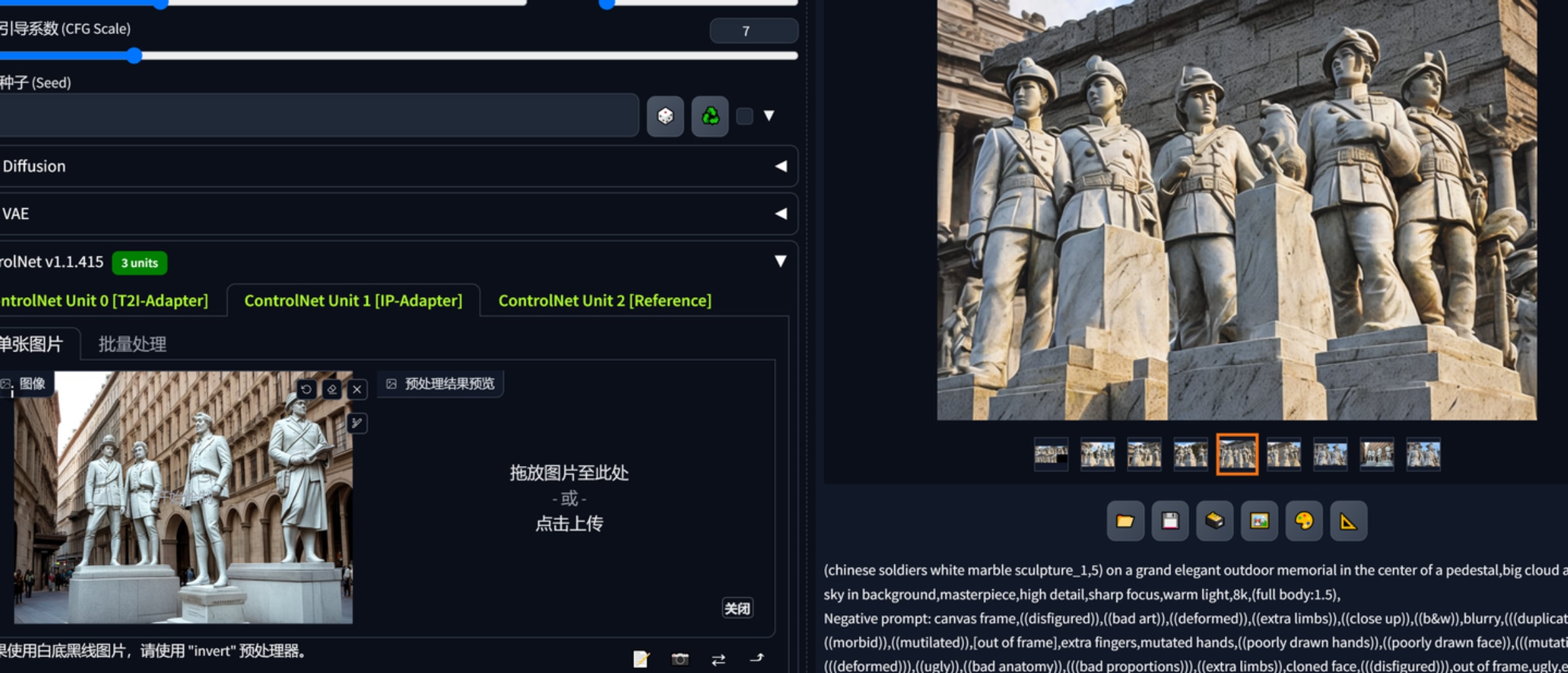
以下为无提示词用ip-adapter生产的图。

以下为无提示词用shuffle生产的图。

以下为无提示词用ip-adapter、t2Iadapter生产的图。

ip-adapter人物,下图1有提示词,下图2没有提示词。可以看出来ip-adapter在布局上高度近似,但面部特征完全不对。

t2I-adapter,下图1为有提示词,下图2为无提示词。可以看出来t2I-adapter对人物的布局、背景、特征都没有提取出来,完全与参考图无关,不过它做的人物解剖学结构很合理,且可以将跳出参考对形体图幅的限制,原参考为半身像,在ip-adapter、reference中是限定死构图的,提示词不管咋搞似乎都会被无视。
reference,下图1为无提示词,下图2为有提示词。可以看出来reference对面部、服装、光影特征把控的很好,但是人物的造型、布局不合理。
看到这里理论上来说结合ip-adapter(控制站位布局)、t2i-adapter(增加站位布局多样化)、reference(控制面部、服饰、光影特征)三者可以将参考图的人像衍生出风格近似、不同布局的图?可惜sd目前不支持多通道controlnet用xyz图表控制变量。
下图为ip-adapter 0.7 t2i-adapter 0.35 reference 1.2 Style Fidelity 0.7这个设定下所有的人物、背景都和原参考图的布局太相似了。
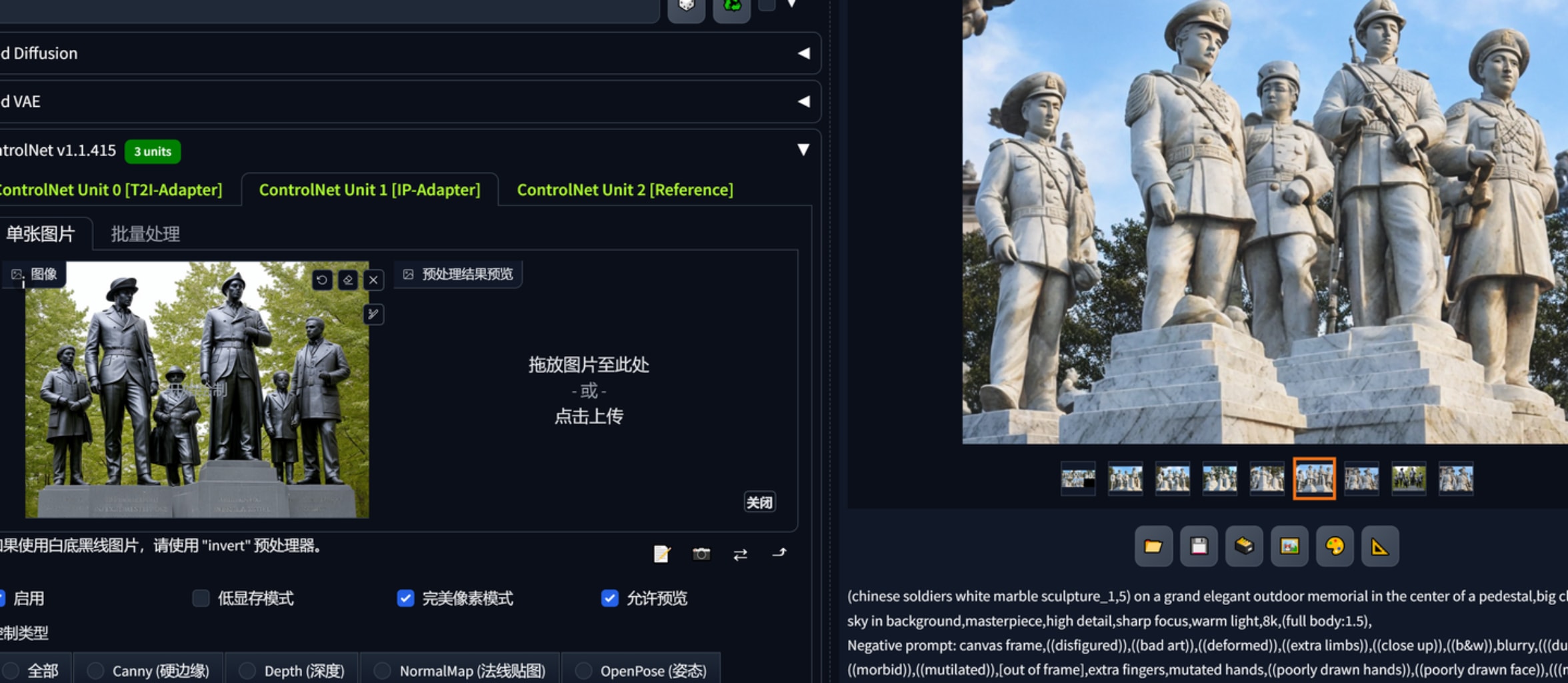
下图为t2i-adapter 0.9 reference 1.05 Style Fidelity 0.7可以看到有人物的全身像了,且人物特征把我的还可以,也没有太大的结构问题。
我试图用另一个完全不同布局的全身像来取代ip-adapter中的半身像来改变人物的布局,尽管只有0.5的权重出来的人面部特征、服饰、解剖学结构都偏差很大,看起来不正常。换了个布局依旧如此
在调整到0.3之后看起来可以勉强凑合了。
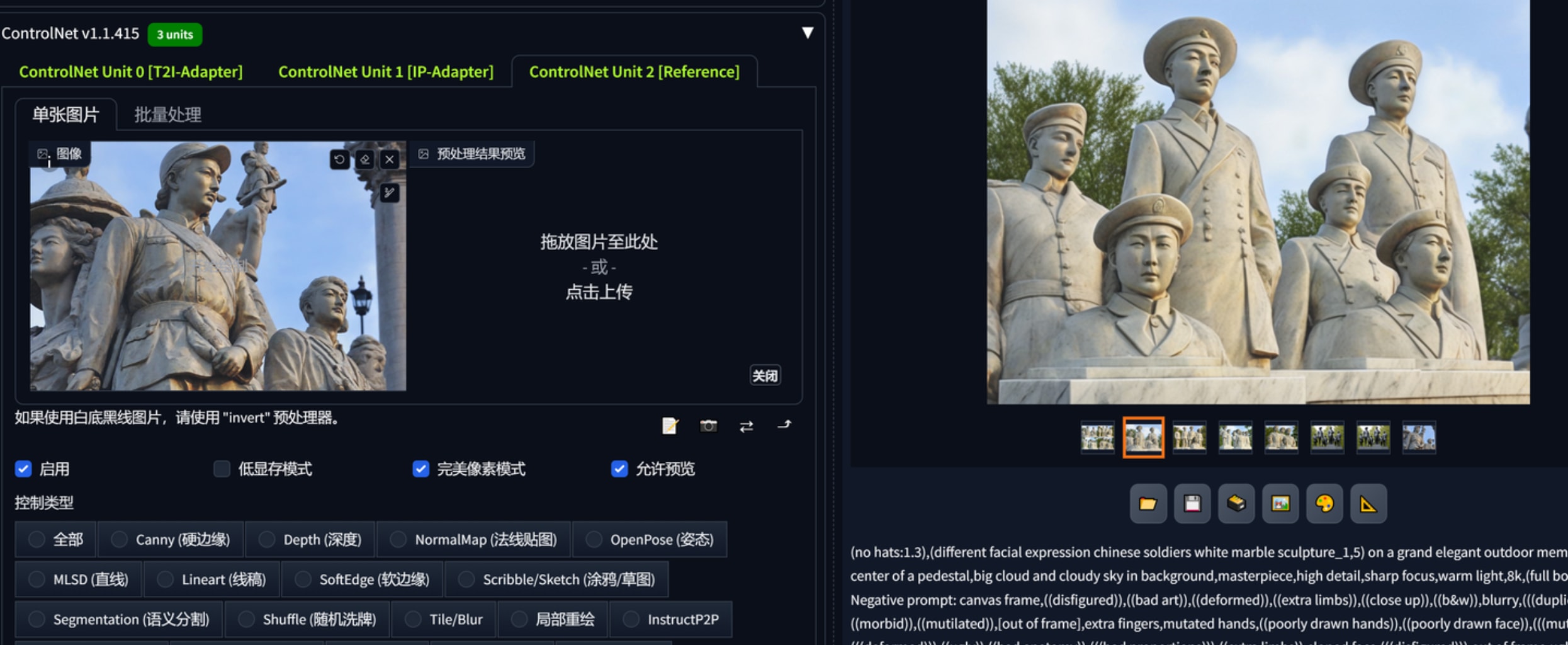
我把尺寸从1024x768调整到1536x1024结果似乎又不太行了,出现了解剖学结构错误
诡异的是哪怕换了一个reference,帽子的款式明显不一样,提示词强调no hats还是全员带帽子。下图2,在3个参考都换成这个图后,依旧难以得到多样化的站姿、表情、发型,看来想用某个满意的雕塑群反推同类不太现实。这会不会和用的大模型有关系呢?
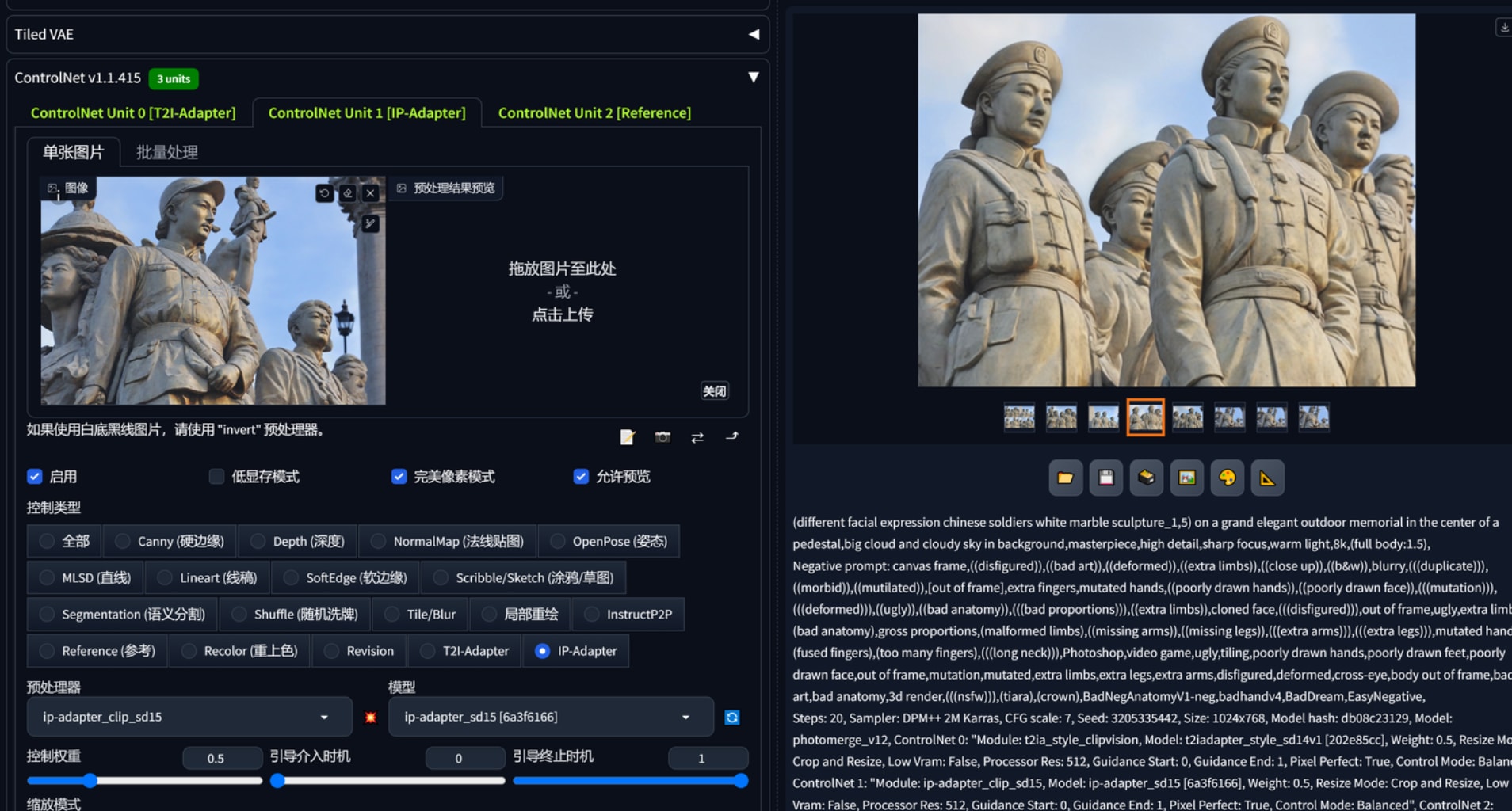
用sdxl的及其衍生模型可以看出来人物面部的特征明显要好于sd普通模型,sd模型出来的脸可以说是千篇一律。因此人物方面要




测试reference权重的影响在xl模型中超过1以上貌似都和1一样了?

换成这个工人维修奇异机器,出来的结果与原先偏差很大。
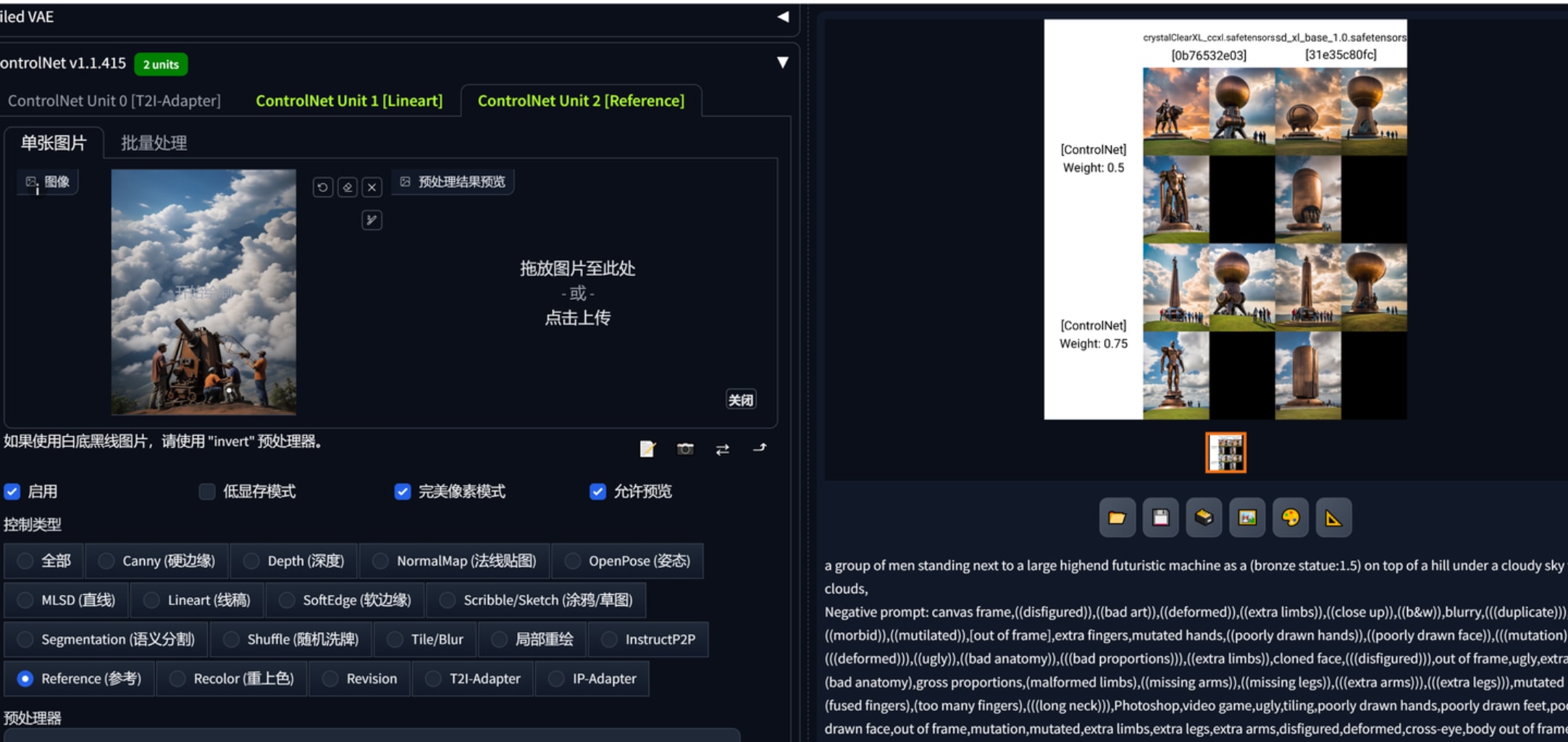
three humen workers as (bronze statue:1.5),standing next to a large highend futuristic machine as a (bronze statue:1.5) on top of a hill under a cloudy sky with clouds,
加了一个depth控制,0.75以下形体偏的很厉害。材质方面基本可以保证了。作为雕塑效果参考,勉勉强强。




我试图结合这两个图来做雕塑装饰参考,depth zoe的计算不理想出来的图完全走形了。


0.9-1.1可以看到crystalXL比sdxl原始模型在depth控制下更遵循我们的需求。depth的好处在于重排一些物体的构造让电脑给出出人意料但又在清理之中的构造。


用canny控制,1以下的偏差很大。canny给出的构造更接近原参考图。


lineart控制不适合出复杂体块的雕塑概念。

通过agent scheduler这个插件可以批量安排任务,因此以后关于ai作图,放到临近吃饭的时候批量安排。
评论